Tidying data
Lecture 6
Dr. Benjamin Soltoff
Cornell University
INFO 5001 - Fall 2025
September 11, 2025
Announcements
Announcements
- Homework 02 tomorrow
Learning objectives
- Define tidy data and its characteristics
- Identify the relevance of structuring data in a tidy format
- Review common methods for tidying data using {tidyr}
- Practice tidying data
Tidying datasets
Tidying datasets
What makes a dataset “tidy”?
02:00

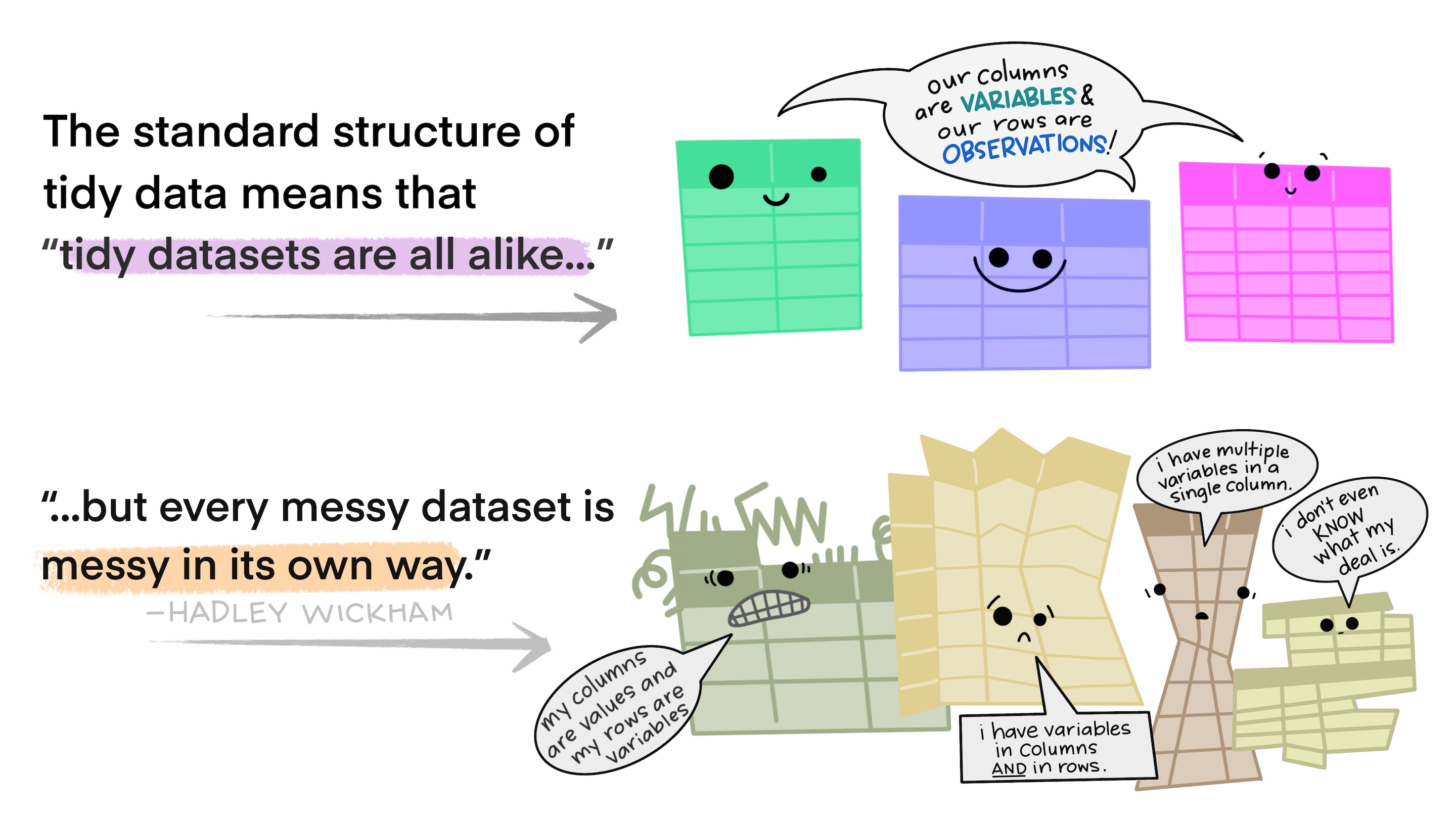
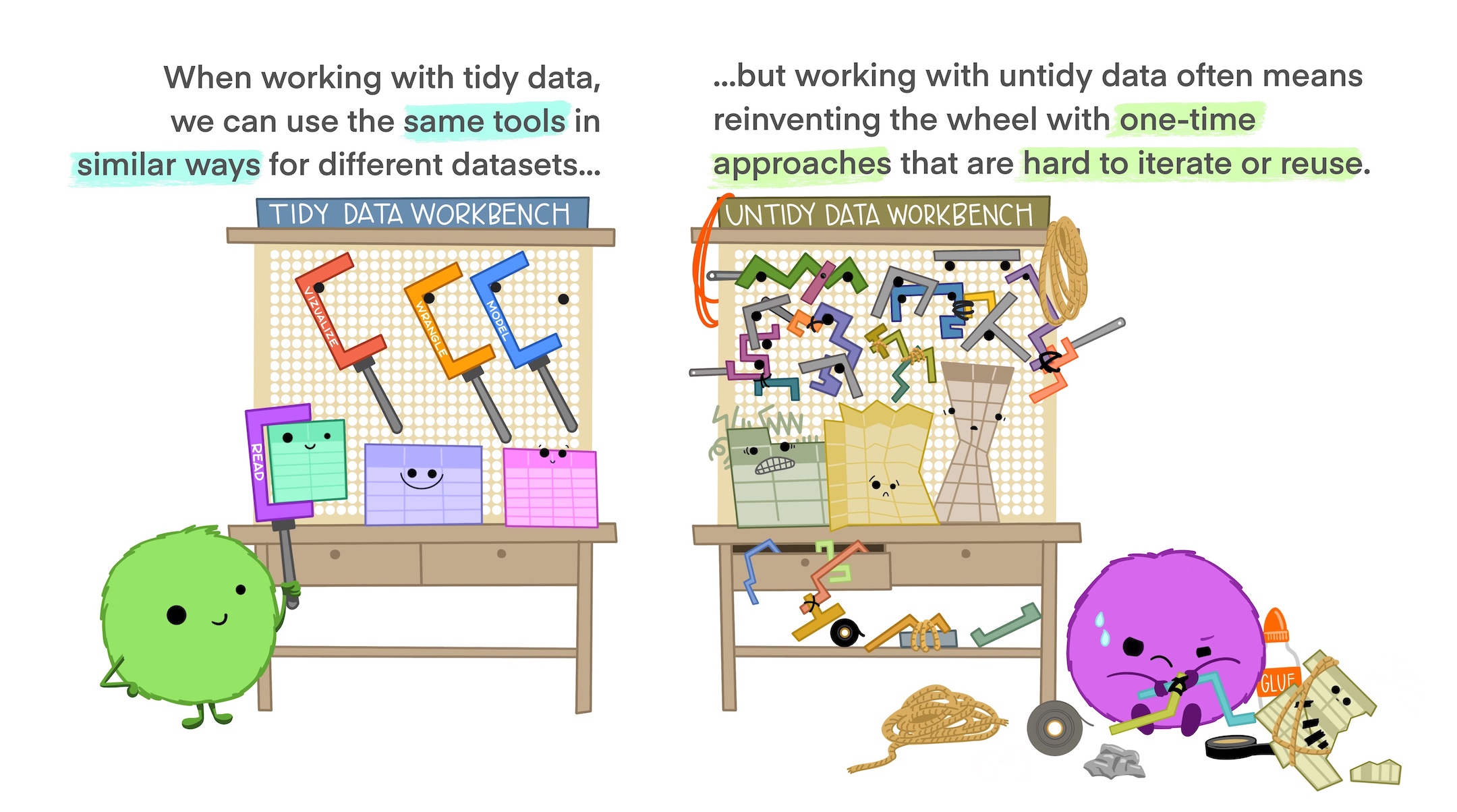


Illustration credit: Tidy Data for reproducibility, efficiency, and collaboration
Application exercise
ae-04
Note
- Go to the course GitHub org and find your
ae-04(repo name will be suffixed with your GitHub name). - Clone the repo in Positron, run
renv::restore()to install the required packages, open the Quarto document in the repo, and follow along and complete the exercises. - Render, commit, and push your edits by the AE deadline – end of the day
Wrap up
Recap
- Data sets should not be labeled as wide or long but they can be made wider or longer for a certain analysis that requires a certain format
- When pivoting longer, variable names that turn into values are characters by default. If you need them to be in another format, you need to explicitly make that transformation, which you can do so within the
pivot_longer()function. - You can tweak a plot forever, but at some point the tweaks are likely not very productive. However, you should always be critical of defaults (however pretty they might be) and see if you can improve the plot to better portray your data / results / what you want to communicate.