Scraping data from the web
Lecture 10
Dr. Benjamin Soltoff
Cornell University
INFO 5001 - Fall 2025
September 25, 2025
Announcements
Announcements
- Quiz 01 tomorrow
- Complete group project preference survey by noon
- No homework this week
Learning objectives
- Define HTML and CSS selectors
- Introduce the {rvest} package for reproducible web scraping
- Demonstrate how to extract information from HTML pages
- Practice scraping data
Reading data into R
- Local data files
- Databases
- Web scraping
- Application programming interfaces (APIs)
Scraping the web: what? why?
Increasing amount of data is available on the web
These data are provided in an unstructured format: you can always copy & paste, but it’s time-consuming and prone to errors
Web scraping is the process of extracting data from the source code of websites reproducibly and transforming it into a structured dataset
HyperText Markup Language
- Much of the data on the web is still largely available as HTML
- It is structured (hierarchical / tree based), but it’s often not available in a form useful for analysis (flat / tidy).
{rvest}
- The {rvest} package makes basic processing and manipulation of HTML data straight forward
- It’s designed to work with pipelines built with
|> - rvest.tidyverse.org

Core {rvest} functions
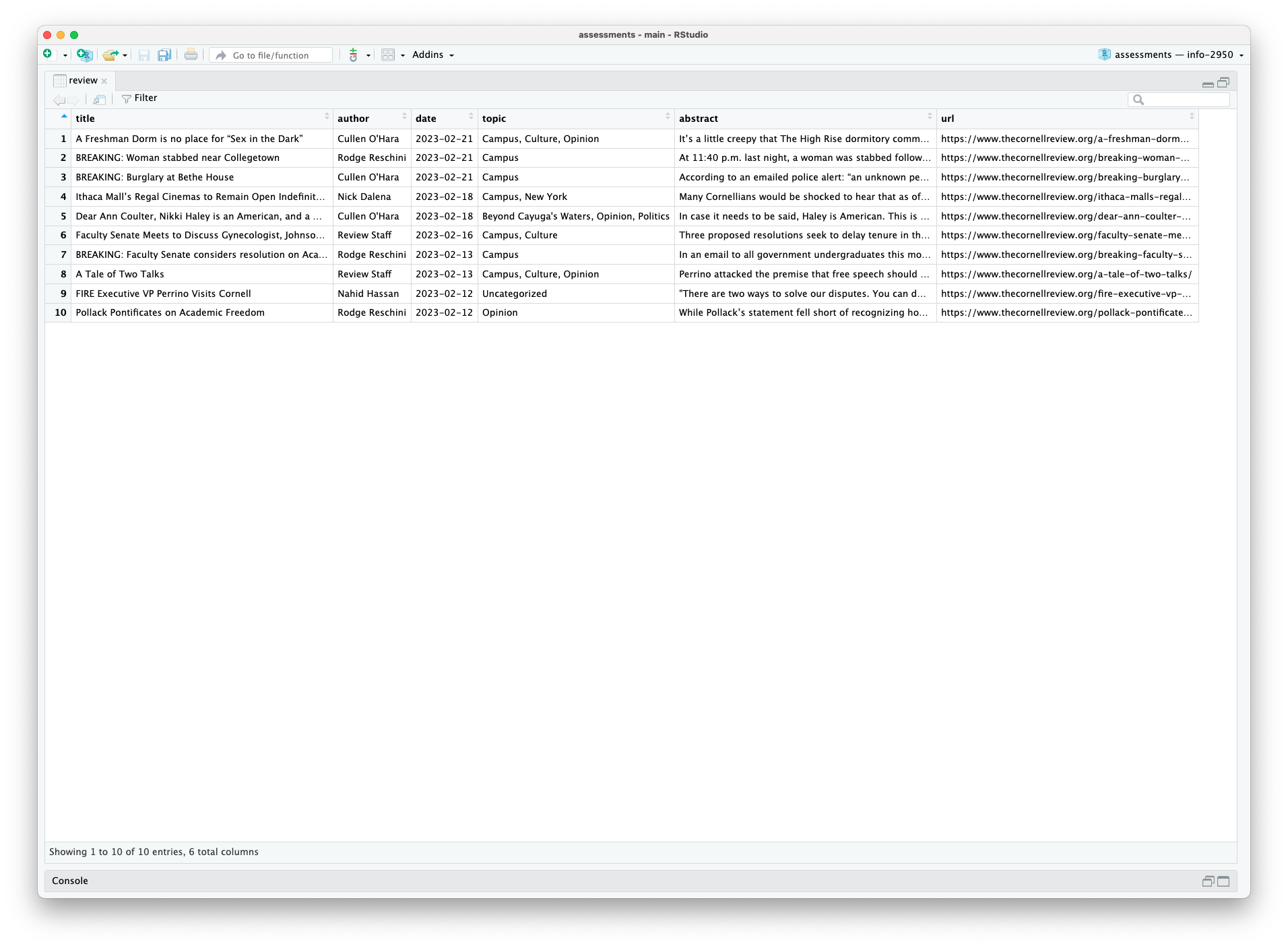
read_html()- Read HTML data from a url or character stringhtml_element()/html_elements()- Select a specified element(s) from HTML documenthtml_table()- Parse an HTML table into a data framehtml_text()- Extract text from an elementhtml_text2()- Extract text from an element and lightly format it to match how text looks in the browserhtml_name()- Extract elements’ nameshtml_attr()/html_attrs()- Extract a single attribute or all attributes
Application exercise
Goal
- Scrape data and organize it in a tidy format in R
- Perform light text parsing to clean data
ae-08
Note
- Go to the course GitHub org and find your
ae-08(repo name will be suffixed with your GitHub name). - Clone the repo in Positron, run
renv::restore()to install the required packages, open the Quarto document in the repo, and follow along and complete the exercises. - Render, commit, and push your edits by the AE deadline – end of the day
A new R workflow
When working in a Quarto document, your analysis is re-run each time you render
If web scraping in a Quarto document, you’d be re-scraping the data each time you render, which is undesirable (and not nice)!
An alternative workflow:
- Use an R script to save your code
- Save interim data scraped using the code in the script as CSV or RDS files
- Use the saved data in your analysis in your Quarto document
Web scraping considerations
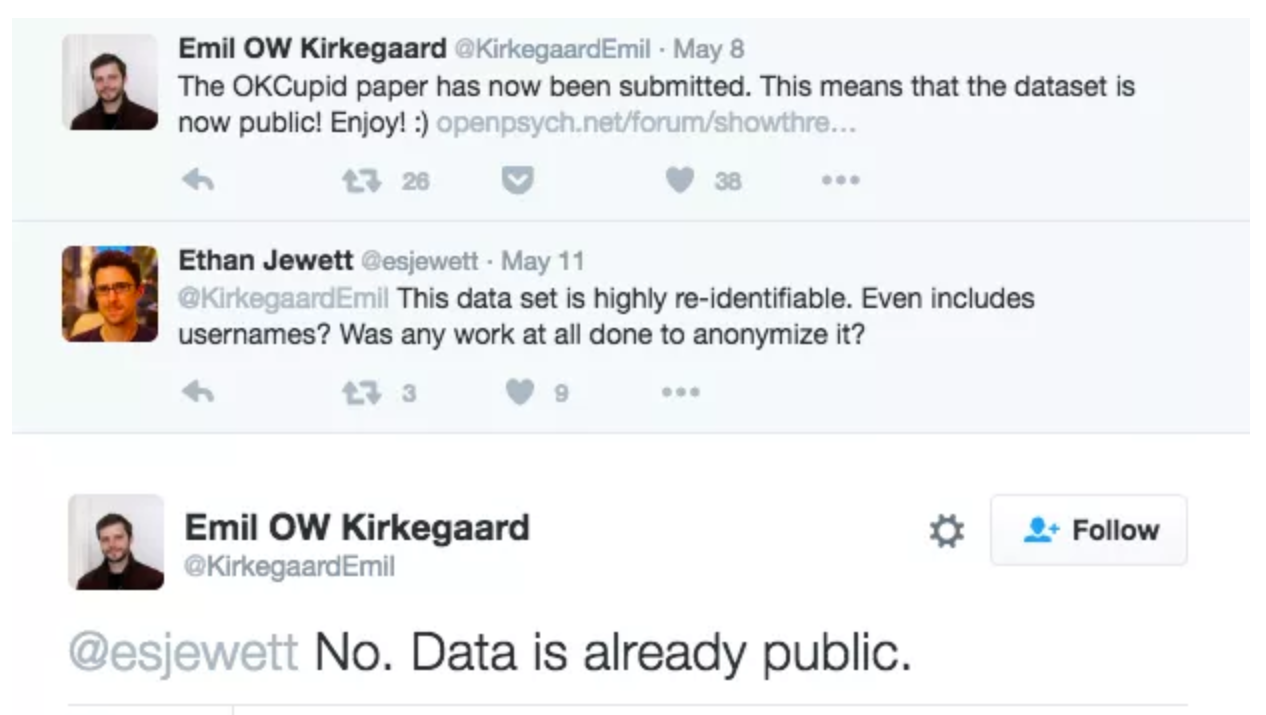
Ethics: “Can you?” vs “Should you?”
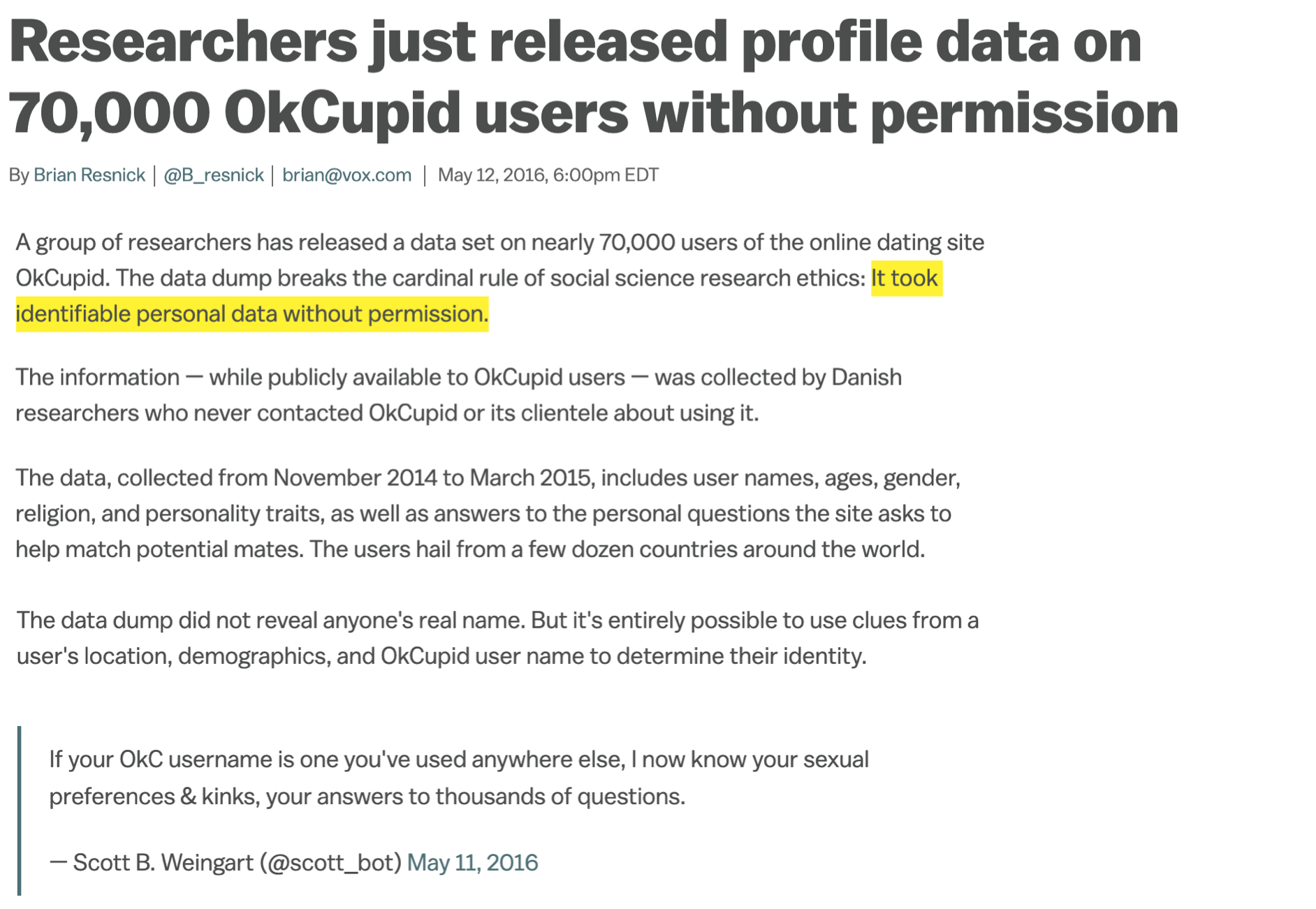
Source: Brian Resnick, Researchers just released profile data on 70,000 OkCupid users without permission, Vox.
“Can you?” vs “Should you?”
Challenges: Unreliable formatting
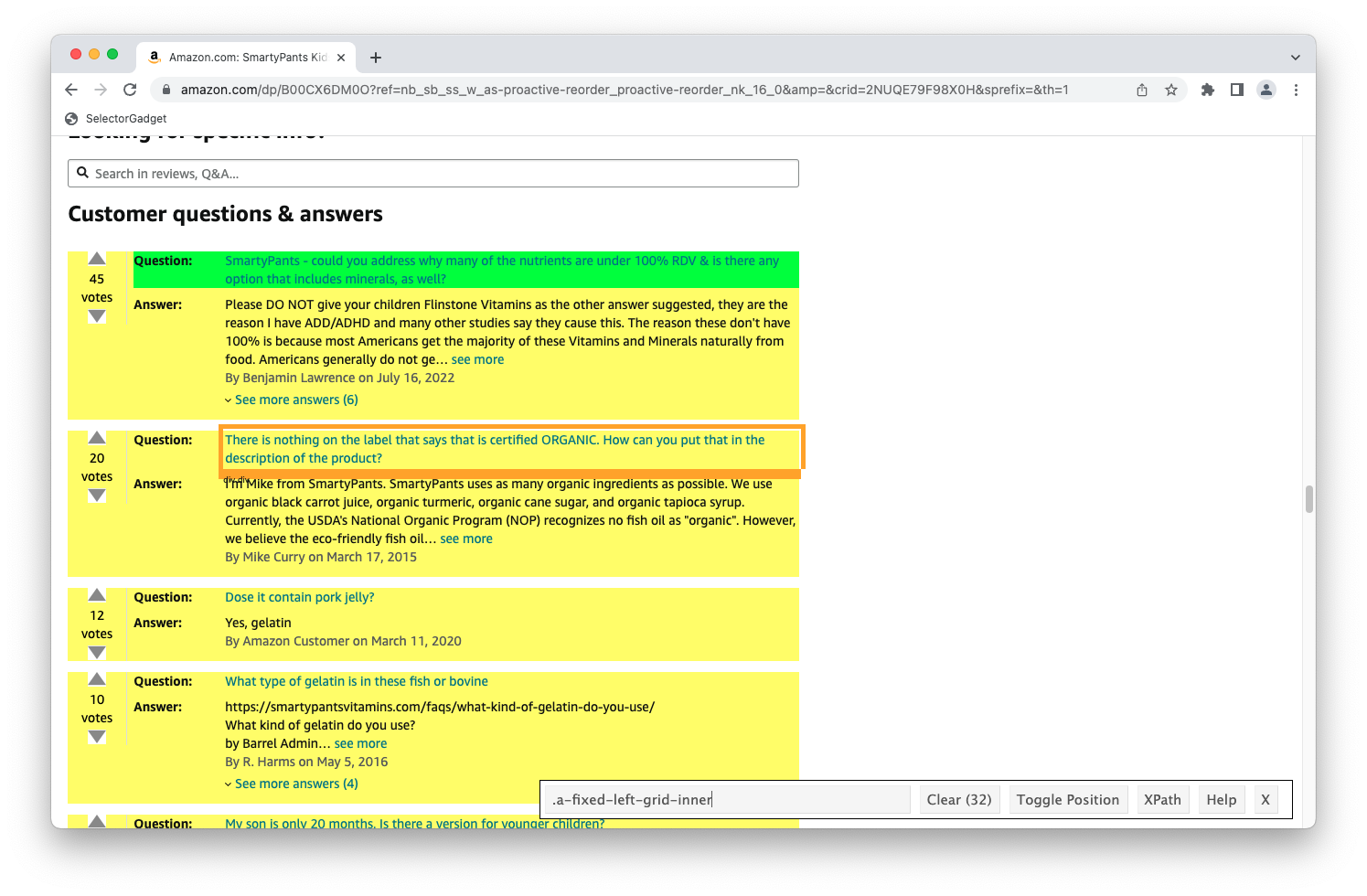
Challenges: Data broken into many pages
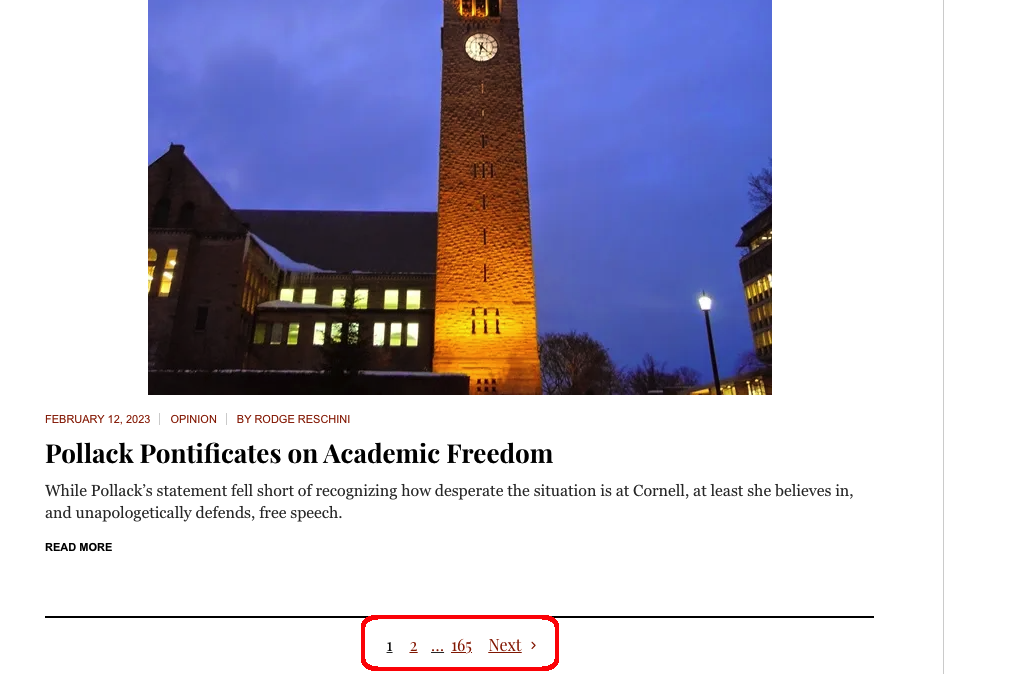
Challenges: Non-static content
- Content generated dynamically through the use of JavaScript
- Search
- Filtering
- Infinite scrolling
- Authenticated web pages
- Requires a live browser session to access programmatically
Wrap up
Recap
- Use the SelectorGadget to identify elements you want to grab
- Use {rvest} to first read the whole page (into R) and then parse the object you’ve read in to the elements you’re interested in
- Put the components together in a data frame and analyze it like you analyze any other data
Acknowledgments
- Some slides are derived from Data Science in a Box and licensed under CC BY-SA 4.0.