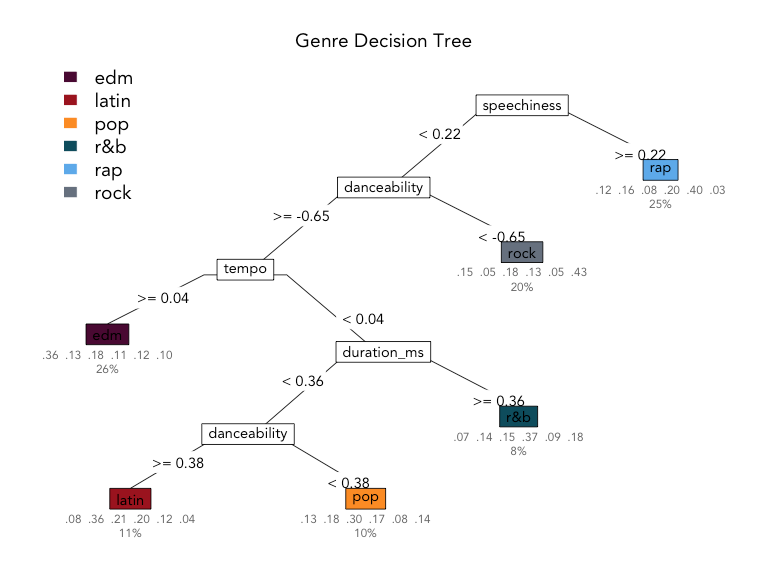
Decision Tree Model Specification (classification)
Main Arguments:
tree_depth = 3
Computational engine: rpart
tree_depth
Cap the maximum tree depth.
A method to stop the tree early. Used to prevent overfitting.
tree_mod |>set_args(tree_depth =30)
min_n
Set minimum n to split at any node.
Another early stopping method. Used to prevent overfitting.
tree_mod |>set_args(min_n =20)
Quiz
What value of min_n would lead to the most overfit tree?
min_n = 1
Recap: early stopping
parsnip arg
rpart arg
default
overfit?
tree_depth
maxdepth
30
⬆️
min_n
minsplit
20
⬇️
cost_complexity
Adds a cost or penalty to error rates of more complex trees.
A way to prune a tree. Used to prevent overfitting.
tree_mod |>set_args(cost_complexity = .01)
Closer to zero ➡️ larger trees.
Higher penalty ➡️ smaller trees.
Consider the bonsai
Small pot
Strong shears
Consider the bonsai
Small potEarly stopping
Strong shearsPruning
Recap: early stopping & pruning
parsnip arg
rpart arg
default
overfit?
tree_depth
maxdepth
30
⬆️
min_n
minsplit
20
⬇️
cost_complexity
cp
.01
⬇️
Axiom
There is an inverse relationship between model accuracy and model interpretability.
Random forests
rand_forest()
Specifies a random forest model
rand_forest(mtry =4, trees =500, min_n =1)
either mode works!
rand_forest()
Specifies a random forest model
rand_forest(engine ="ranger", # default computational enginemtry =4, # predictors seen at each nodetrees =500, # trees per forestmin_n =1# smallest node allowed)
⏱️ Your turn 2
Create a new parsnip model called rf_mod, which will learn an ensemble of classification trees from our training data using the ranger engine. Update your tree_wf with this new model.
Fit your workflow with 10-fold cross-validation and compare the ROC AUC of the random forest to your single decision tree model — which predicts the assessment set better?
Hint: you’ll need https://www.tidymodels.org/find/parsnip/
Challenge: Fit 3 more random forest models, each using 3, 5, and 8 variables at each split. Update your rf_wf with each new model. Which value maximizes the area under the ROC curve?
# here comes the actual ML bits…# pick model to tunerf_tuner <-rand_forest(engine ="ranger",mtry =tune(),min_n =tune()) |>set_mode("classification")rf_wf <-workflow() |>add_formula(children ~ .) |>add_model(rf_tuner)rf_results <- rf_wf |>tune_grid(resamples = hotels_folds,control =control_grid(save_pred =TRUE,save_workflow =TRUE ) )
# fit using best hyperparameter values# and full training setbest_rf <-fit_best(rf_results)best_rf
══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Formula
Model: rand_forest()
── Preprocessor ────────────────────────────────────────────────────────────────
children ~ .
── Model ───────────────────────────────────────────────────────────────────────
Ranger result
Call:
ranger::ranger(x = maybe_data_frame(x), y = y, mtry = min_cols(~9L, x), min.node.size = min_rows(~15L, x), num.threads = 1, verbose = FALSE, seed = sample.int(10^5, 1), probability = TRUE)
Type: Probability estimation
Number of trees: 500
Sample size: 3600
Number of independent variables: 21
Mtry: 9
Target node size: 15
Variable importance mode: none
Splitrule: gini
OOB prediction error (Brier s.): 0.1209798
# predict probabilities for test setbind_cols( hotels_test,predict(best_rf, new_data = hotels_test, type ="prob")) |># generate ROC curveroc_curve(truth = children, .pred_children) |>autoplot()
Recap
Decision trees are a nonlinear, naturally interactive model for classification and regression tasks
Simple decision trees can be easily interpreted, but also less accurate
Random forests are ensembles of decision trees used to aggregate predictions for improved performance
Models with hyperparameters require tuning in order to achieve optimal performance
Once the optimal model is achieved via cross-validation, fit the model a final time using the entire training set and evaluate its performance using the test set
It’s basically Hunger Games and Game of Thrones and Dragonheart rolled into one story. The world building is excellent, the characters have depth, there is snappy dialogue. It’s about dragon riders and rebellion and magic.