Text analysis: fundamentals and sentiment analysis
Lecture 22
Dr. Benjamin Soltoff
Cornell University
INFO 5001 - Fall 2023
2023-11-13
Announcements
Announcements
- Lab 06
- Homework 05
- Project (draft) deliverables
Core text data workflows
Basic workflow for text analysis
- Obtain your text sources
- Extract documents and move into a corpus
- Transformation
- Extract features
- Perform analysis
Obtain your text sources
- Web sites/APIs
- Databases
- PDF documents
- Digital scans of printed materials
Extract documents and move into a corpus
- Text corpus
- Typically stores the text as a raw character string with metadata and details stored with the text
Transformation
- Tag segments of speech for part-of-speech (nouns, verbs, adjectives, etc.) or entity recognition (person, place, company, etc.)
- Standard text processing
- Convert to lower case
- Remove punctuation
- Remove numbers
- Remove stopwords
- Remove domain-specific stopwords
- Stemming
Extract features
- Convert the text string into some sort of quantifiable measures
- Bag-of-words model
- Term frequency vector
- Term-document matrix
- Ignores context
- Word embeddings
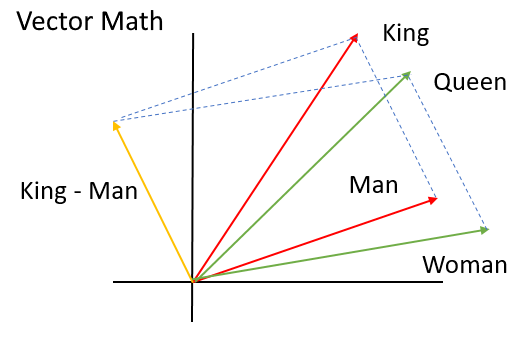
Word embeddings
Perform analysis
- Basic
- Word frequency
- Collocation
- Dictionary tagging
- Advanced
- Document classification
- Corpora comparison
- Topic modeling
tidytext
- Using tidy data principles can make many text mining tasks easier, more effective, and consistent with tools already in wide use
- Learn more at tidytextmining.com

What is tidy text?
text <- c(
"Yeah, with a boy like that it's serious",
"There's a boy who is so wonderful",
"That girls who see him cannot find back home",
"And the gigolos run like spiders when he comes",
"'Cause he is Eros and he's Apollo",
"Girls, with a boy like that it's serious",
"Senoritas, don't follow him",
"Soon, he will eat your hearts like cereals",
"Sweet Lolitas, don't go",
"You're still young",
"But every night they fall like dominoes",
"How he does it, only heaven knows",
"All the other men turn gay wherever he goes (wow!)"
)
text [1] "Yeah, with a boy like that it's serious"
[2] "There's a boy who is so wonderful"
[3] "That girls who see him cannot find back home"
[4] "And the gigolos run like spiders when he comes"
[5] "'Cause he is Eros and he's Apollo"
[6] "Girls, with a boy like that it's serious"
[7] "Senoritas, don't follow him"
[8] "Soon, he will eat your hearts like cereals"
[9] "Sweet Lolitas, don't go"
[10] "You're still young"
[11] "But every night they fall like dominoes"
[12] "How he does it, only heaven knows"
[13] "All the other men turn gay wherever he goes (wow!)"What is tidy text?
# A tibble: 13 × 2
line text
<int> <chr>
1 1 Yeah, with a boy like that it's serious
2 2 There's a boy who is so wonderful
3 3 That girls who see him cannot find back home
4 4 And the gigolos run like spiders when he comes
5 5 'Cause he is Eros and he's Apollo
6 6 Girls, with a boy like that it's serious
7 7 Senoritas, don't follow him
8 8 Soon, he will eat your hearts like cereals
9 9 Sweet Lolitas, don't go
10 10 You're still young
11 11 But every night they fall like dominoes
12 12 How he does it, only heaven knows
13 13 All the other men turn gay wherever he goes (wow!)What is tidy text?
Counting words
Application exercise

ae-20
- Go to the course GitHub org and find your
ae-20(repo name will be suffixed with your GitHub name). - Clone the repo in RStudio Workbench, open the Quarto document in the repo, and follow along and complete the exercises.
- Render, commit, and push your edits by the AE deadline – end of tomorrow
Recap
- tidytext allows you to structure text data in a format conducive to exploratory analysis and wrangling/visualization with tidyverse
- Tokenizing is a process of converting raw character strings to recognizable features
- Remove non-informative stop words to reduce noise in the text data
- tf-idf measures the importance of frequently occurring tokens, increasing the weight for tokens that are not used very much across the corpus
- Dictionary-based sentiment analysis provides a rough classification of text into positive/negative sentiments
Only a few weeks left in the semester!