AE 10: Iterating in R
Suggested answers
Packages
We will use the following packages in this application exercise.
- {tidyverse}: For data import, wrangling, and visualization.
- {rvest}: For scraping HTML files.
- {robotstxt}: For verifying if we can scrape a website.
Part 1: Iterating over columns
Your turn: Write a function that summarizes multiple specified columns of a data frame and calculates their arithmetic mean and standard deviation using across().
# A tibble: 3 × 5
species bill_len_mean bill_len_sd flipper_len_mean flipper_len_sd
<fct> <dbl> <dbl> <dbl> <dbl>
1 Adelie 38.8 2.66 190. 6.54
2 Chinstrap 48.8 3.34 196. 7.13
3 Gentoo 47.5 3.08 217. 6.48 bill_len_mean bill_len_sd bill_dep_mean bill_dep_sd flipper_len_mean
1 43.92193 5.459584 17.15117 1.974793 200.9152
flipper_len_sd body_mass_mean body_mass_sd
1 14.06171 4201.754 801.9545Part 2: Data scraping
See the code below stored in iterate-cornell-review.R.
# load packages
library(tidyverse)
library(rvest)
library(robotstxt)
# check that we can scrape data from the cornell review
paths_allowed("https://www.thecornellreview.org/")
# read the first page
page <- read_html("https://www.thecornellreview.org/")
# extract desired components
titles <- html_elements(x = page, css = "#main .read-title a") |>
html_text2()
authors <- html_elements(x = page, css = "#main .byline a") |>
html_text2()
article_dates <- html_elements(x = page, css = "#main .posts-date") |>
html_text2()
topics <- html_elements(x = page, css = "#main .cat-links") |>
html_text2()
abstracts <- html_elements(x = page, css = ".post-description") |>
html_text2()
post_urls <- html_elements(x = page, css = ".aft-readmore") |>
html_attr(name = "href")
# create a tibble with this data
review_raw <- tibble(
title = titles,
author = authors,
date = article_dates,
topic = topics,
description = abstracts,
url = post_urls
)
# clean up the data
review <- review_raw |>
mutate(
date = mdy(date),
description = str_remove(string = description, pattern = "\nRead More")
)
######## write a function to scrape a single page and use a map() function
######## to iterate over the first ten pages
# convert to a function
scrape_review <- function(url){
# pause for a couple of seconds to prevent rapid HTTP requests
Sys.sleep(2)
# read the first page
page <- read_html(url)
# extract desired components
titles <- html_elements(x = page, css = "#main .read-title a") |>
html_text2()
authors <- html_elements(x = page, css = "#main .byline a") |>
html_text2()
article_dates <- html_elements(x = page, css = "#main .posts-date") |>
html_text2()
topics <- html_elements(x = page, css = "#main .cat-links") |>
html_text2()
abstracts <- html_elements(x = page, css = ".post-description") |>
html_text2()
post_urls <- html_elements(x = page, css = ".aft-readmore") |>
html_attr(name = "href")
# create a tibble with this data
review_raw <- tibble(
title = titles,
author = authors,
date = article_dates,
topic = topics,
description = abstracts,
url = post_urls
)
# clean up the data
review <- review_raw |>
mutate(
date = mdy(date),
description = str_remove(string = description, pattern = "\nRead More")
)
# export the resulting data frame
return(review)
}
# test function
## page 1
scrape_review(url = "https://www.thecornellreview.org/page/1/")
## page 2
scrape_review(url = "https://www.thecornellreview.org/page/2/")
# create a vector of URLs
page_nums <- 1:10
cr_urls <- str_glue("https://www.thecornellreview.org/page/{page_nums}/")
cr_urls
# map function over URLs
cr_reviews <- map(.x = cr_urls, .f = scrape_review, .progress = TRUE) |>
list_rbind()
# write data
write_csv(x = cr_reviews, file = "data/cornell-review-all.csv")Part 3: Data analysis
Demo: Import the scraped data set.
cr_reviews <- read_csv(file = "data/cornell-review-all.csv")Rows: 100 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): title, author, topic, description, url
date (1): date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.cr_reviews# A tibble: 100 × 6
title author date topic description url
<chr> <chr> <date> <chr> <chr> <chr>
1 Playing the Race Card Revie… 2024-10-07 "Cam… CML and BS… http…
2 Should Joel Malina Be Fired? Revie… 2024-10-07 "Bey… Cornell’s … http…
3 Cornell Drops in 2025 FIRE Free Sp… Revie… 2024-10-03 "Cam… Each year,… http…
4 Interim Expressive Activity Policy… Revie… 2024-10-02 "Cor… On October… http…
5 Daryl Davis To Speak on Race Relat… Revie… 2024-10-01 "Cam… Daryl Davi… http…
6 Happy 100th Birthday, President Ca… Revie… 2024-10-01 "Bey… President … http…
7 Kavita Bala Named Cornell Provost Revie… 2024-09-25 "Cam… On Septemb… http…
8 Ithaca Labor News Revie… 2024-09-25 "Ith… Here are t… http…
9 CML Realizes It Overstepped Social… Revie… 2024-09-25 "Cam… On Wednesd… http…
10 Cornell Republicans to Host Ben Sh… Revie… 2024-09-24 "Ith… On Monday,… http…
# ℹ 90 more rowsDemo: Who are the most prolific authors?
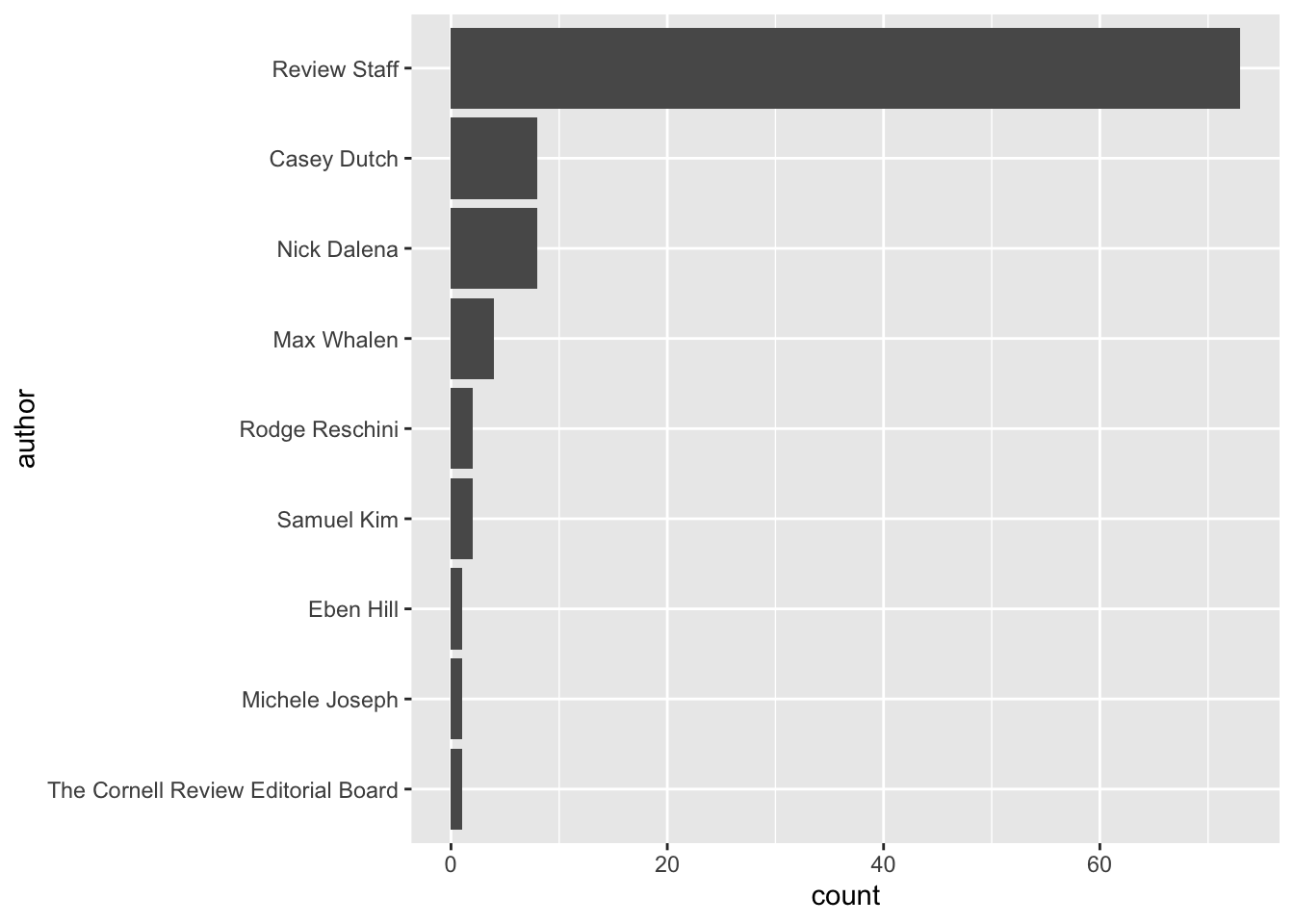
Demo: What topics does The Cornell Review write about?
Not super helpful. Each article can have multiple topics. What is the syntax for this column?
cr_reviews |>
select(topic)# A tibble: 100 × 1
topic
<chr>
1 "Campus"
2 "Beyond Cayuga's Waters"
3 "Campus"
4 "Cornell Politics"
5 "Campus"
6 "Beyond Cayuga's Waters\nUncategorized"
7 "Campus"
8 "Ithaca"
9 "Campus"
10 "Ithaca\nPolitics"
# ℹ 90 more rowsEach topic is separated by a "\n". Since the number of topics varies for each article, we should separate_longer_delim() this column. Instead we can use a stringr function to split them into distinct character strings.
cr_reviews |>
separate_longer_delim(
cols = topic,
delim = "\n"
)# A tibble: 133 × 6
title author date topic description url
<chr> <chr> <date> <chr> <chr> <chr>
1 Playing the Race Card Revie… 2024-10-07 Camp… CML and BS… http…
2 Should Joel Malina Be Fired? Revie… 2024-10-07 Beyo… Cornell’s … http…
3 Cornell Drops in 2025 FIRE Free Sp… Revie… 2024-10-03 Camp… Each year,… http…
4 Interim Expressive Activity Policy… Revie… 2024-10-02 Corn… On October… http…
5 Daryl Davis To Speak on Race Relat… Revie… 2024-10-01 Camp… Daryl Davi… http…
6 Happy 100th Birthday, President Ca… Revie… 2024-10-01 Beyo… President … http…
7 Happy 100th Birthday, President Ca… Revie… 2024-10-01 Unca… President … http…
8 Kavita Bala Named Cornell Provost Revie… 2024-09-25 Camp… On Septemb… http…
9 Ithaca Labor News Revie… 2024-09-25 Itha… Here are t… http…
10 CML Realizes It Overstepped Social… Revie… 2024-09-25 Camp… On Wednesd… http…
# ℹ 123 more rowsNotice the data frame now has additional rows. The unit of analysis is now an article-topic combination, rather than one-row-per-article. Not entirely a tidy structure, but necessary to construct a chart to visualize topic frequency.
cr_reviews |>
separate_longer_delim(
cols = topic,
delim = "\n"
) |>
ggplot(mapping = aes(y = topic)) +
geom_bar()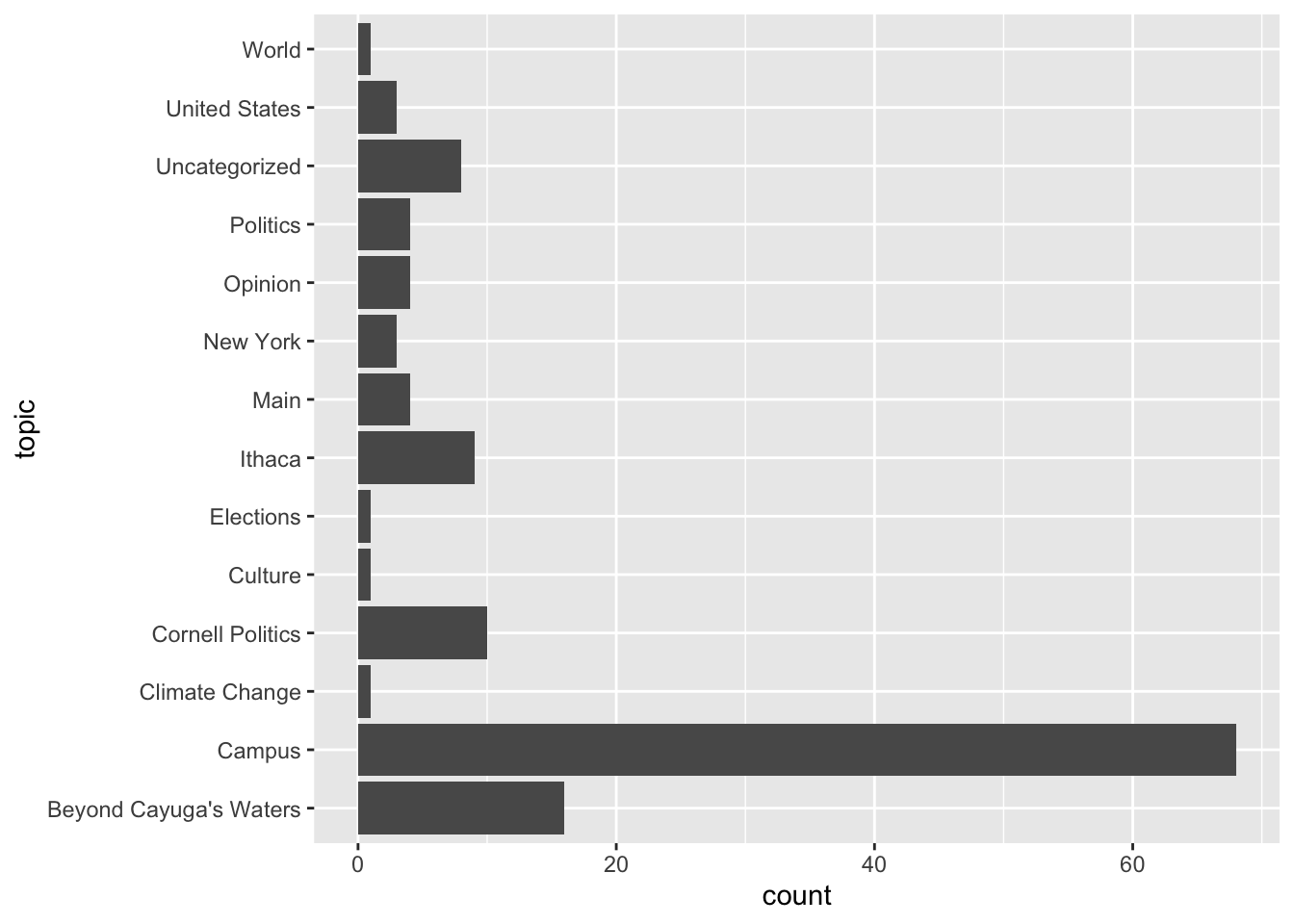
Let’s clean this up like the previous chart.
cr_reviews |>
separate_longer_delim(
cols = topic,
delim = "\n"
) |>
mutate(
topic = fct_infreq(f = topic) |>
fct_rev()
) |>
ggplot(mapping = aes(y = topic)) +
geom_bar()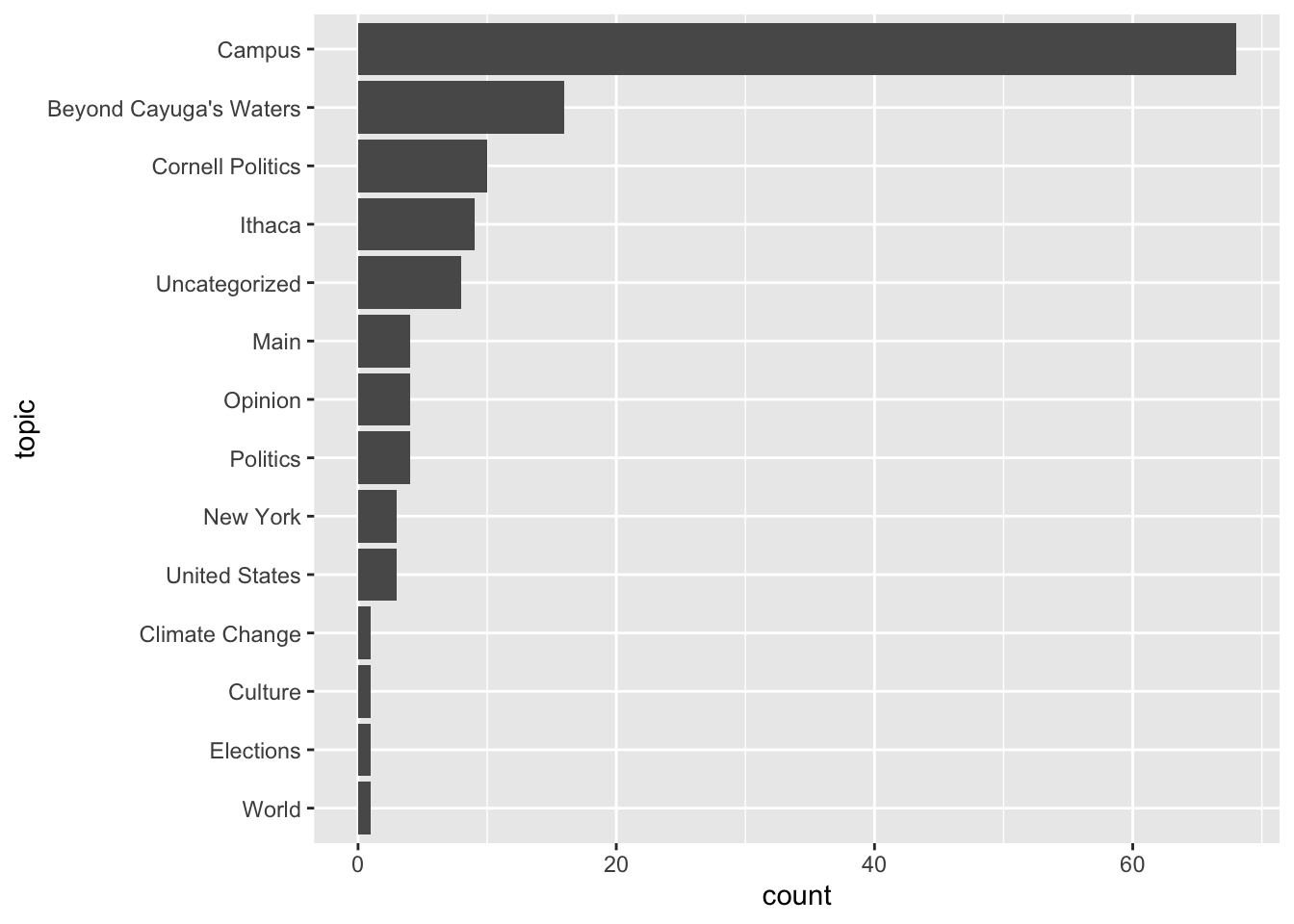
Acknowledgments
- Part 1 is derived from From R User to R Programmer and licensed under CC BY 4.0.
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.5.1 (2025-06-13)
os macOS Tahoe 26.0.1
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/New_York
date 2025-10-03
pandoc 3.4 @ /usr/local/bin/ (via rmarkdown)
quarto 1.8.24 @ /usr/local/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
! package * version date (UTC) lib source
P bit 4.6.0 2025-03-06 [?] RSPM (R 4.5.0)
P bit64 4.6.0-1 2025-01-16 [?] RSPM (R 4.5.0)
P cli 3.6.5 2025-04-23 [?] RSPM (R 4.5.0)
P crayon 1.5.3 2024-06-20 [?] RSPM (R 4.5.0)
P digest 0.6.37 2024-08-19 [?] RSPM (R 4.5.0)
P dplyr * 1.1.4 2023-11-17 [?] RSPM (R 4.5.0)
P evaluate 1.0.4 2025-06-18 [?] RSPM (R 4.5.1)
P farver 2.1.2 2024-05-13 [?] RSPM (R 4.5.0)
P fastmap 1.2.0 2024-05-15 [?] RSPM (R 4.5.0)
P forcats * 1.0.0 2023-01-29 [?] RSPM (R 4.5.0)
P generics 0.1.4 2025-05-09 [?] RSPM (R 4.5.0)
P ggplot2 * 3.5.2 2025-04-09 [?] RSPM (R 4.5.0)
P glue 1.8.0 2024-09-30 [?] RSPM (R 4.5.0)
P gtable 0.3.6 2024-10-25 [?] RSPM (R 4.5.0)
P here 1.0.1 2020-12-13 [?] RSPM (R 4.5.0)
P hms 1.1.3 2023-03-21 [?] RSPM (R 4.5.0)
P htmltools 0.5.8.1 2024-04-04 [?] RSPM (R 4.5.0)
P htmlwidgets 1.6.4 2023-12-06 [?] RSPM (R 4.5.0)
P httr 1.4.7 2023-08-15 [?] RSPM (R 4.5.0)
P jsonlite 2.0.0 2025-03-27 [?] RSPM (R 4.5.0)
P knitr 1.50 2025-03-16 [?] RSPM (R 4.5.0)
P labeling 0.4.3 2023-08-29 [?] RSPM (R 4.5.0)
P lifecycle 1.0.4 2023-11-07 [?] RSPM (R 4.5.0)
P lubridate * 1.9.4 2024-12-08 [?] RSPM (R 4.5.0)
P magrittr 2.0.3 2022-03-30 [?] RSPM (R 4.5.1)
P pillar 1.11.0 2025-07-04 [?] RSPM (R 4.5.1)
P pkgconfig 2.0.3 2019-09-22 [?] RSPM (R 4.5.0)
P purrr * 1.1.0 2025-07-10 [?] RSPM (R 4.5.0)
P R6 2.6.1 2025-02-15 [?] RSPM (R 4.5.0)
P RColorBrewer 1.1-3 2022-04-03 [?] RSPM (R 4.5.0)
P readr * 2.1.5 2024-01-10 [?] RSPM (R 4.5.0)
P renv 1.1.5 2025-07-24 [?] RSPM
P rlang 1.1.6 2025-04-11 [?] RSPM (R 4.5.0)
P rmarkdown 2.29 2024-11-04 [?] RSPM
P robotstxt * 0.7.15 2024-08-29 [?] RSPM
P rprojroot 2.1.0 2025-07-12 [?] RSPM (R 4.5.0)
P rvest * 1.0.4 2024-02-12 [?] RSPM (R 4.5.0)
P scales 1.4.0 2025-04-24 [?] RSPM (R 4.5.0)
P sessioninfo 1.2.3 2025-02-05 [?] RSPM (R 4.5.0)
P stringi 1.8.7 2025-03-27 [?] RSPM (R 4.5.0)
P stringr * 1.5.1 2023-11-14 [?] RSPM (R 4.5.1)
P tibble * 3.3.0 2025-06-08 [?] RSPM (R 4.5.0)
P tidyr * 1.3.1 2024-01-24 [?] RSPM (R 4.5.0)
P tidyselect 1.2.1 2024-03-11 [?] RSPM (R 4.5.0)
P tidyverse * 2.0.0 2023-02-22 [?] RSPM (R 4.5.0)
P timechange 0.3.0 2024-01-18 [?] RSPM (R 4.5.0)
P tzdb 0.5.0 2025-03-15 [?] RSPM (R 4.5.0)
P utf8 1.2.6 2025-06-08 [?] RSPM (R 4.5.0)
P vctrs 0.6.5 2023-12-01 [?] RSPM (R 4.5.0)
P vroom 1.6.5 2023-12-05 [?] RSPM (R 4.5.1)
P withr 3.0.2 2024-10-28 [?] RSPM (R 4.5.0)
P xfun 0.52 2025-04-02 [?] RSPM (R 4.5.1)
P xml2 1.3.8 2025-03-14 [?] RSPM (R 4.5.1)
P yaml 2.3.10 2024-07-26 [?] RSPM (R 4.5.0)
[1] /Users/bcs88/Projects/info-5001/course-site/renv/library/macos/R-4.5/aarch64-apple-darwin20
[2] /Users/bcs88/Library/Caches/org.R-project.R/R/renv/sandbox/macos/R-4.5/aarch64-apple-darwin20/4cd76b74
* ── Packages attached to the search path.
P ── Loaded and on-disk path mismatch.
──────────────────────────────────────────────────────────────────────────────