AE 04: Pivoting Cornell Degrees
Suggested answers
Goal
Our ultimate goal in this application exercise is to make the following data visualization.
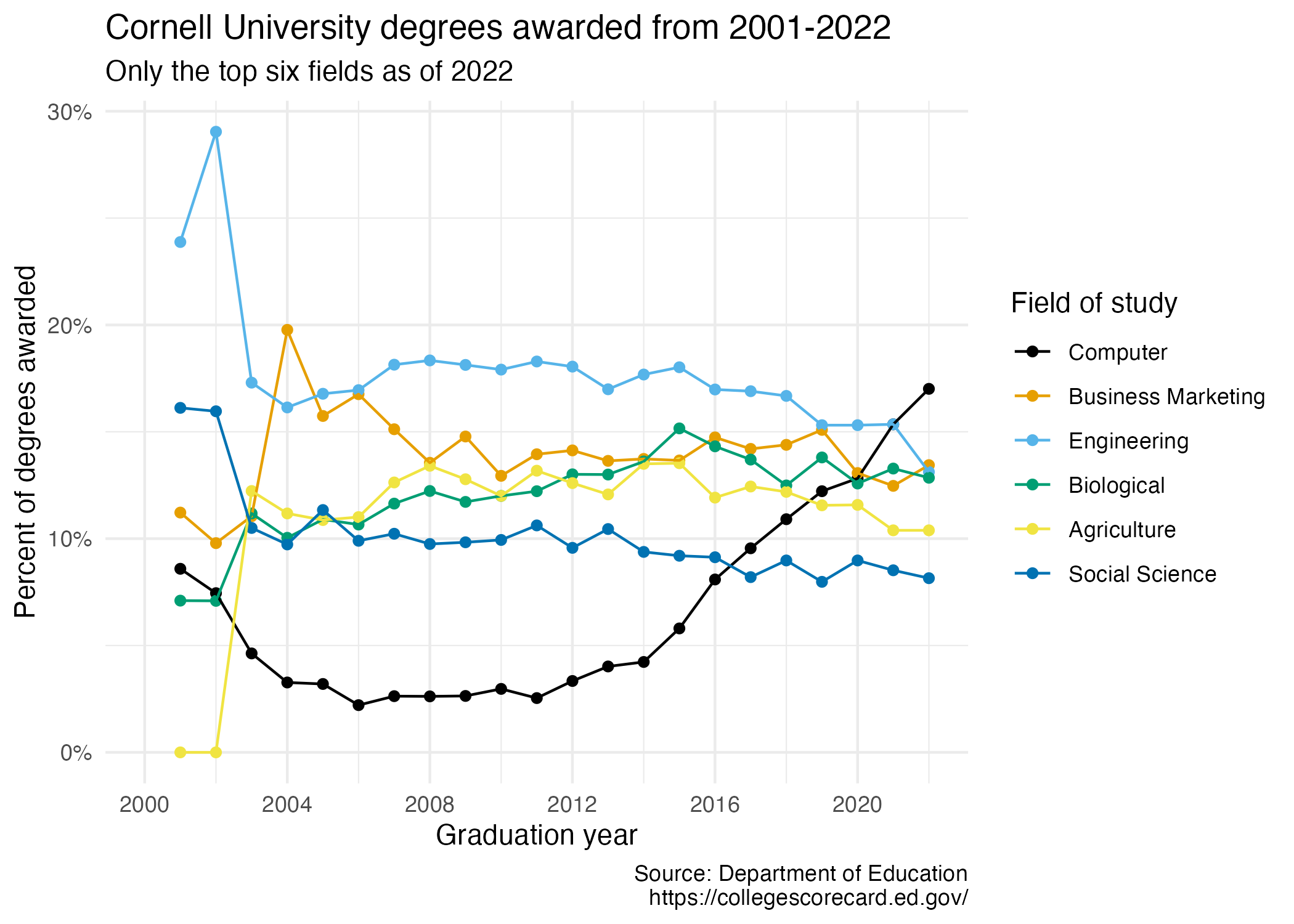
- Your turn (3 minutes): Take a close look at the plot and describe what it shows in 2-3 sentences.
Add response here.
Data
The data come from the Department of Education’s College Scorecard.
They make the data available through online dashboards and an API, but I’ve prepared the data for you in a CSV file.
And let’s take a look at the data.
cornell_deg# A tibble: 6 × 28
field_of_study `1996` `1997` `1998` `1999` `2000` `2001` `2002` `2003` `2004`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Computer 0.0421 0.0497 0.0581 0.0716 0.0684 0.0859 0.0745 0.0463 0.0327
2 Business Marke… 0.108 0.109 0.110 0.105 0.123 0.112 0.0979 0.110 0.198
3 Engineering 0.268 0.292 0.264 0.282 0.258 0.239 0.290 0.173 0.161
4 Biological 0.0983 0.102 0.105 0.103 0.107 0.071 0.0709 0.112 0.100
5 Agriculture 0 0 0 0 0 0 0 0.122 0.112
6 Social Science 0.114 0.137 0.138 0.134 0.147 0.161 0.160 0.105 0.0973
# ℹ 18 more variables: `2005` <dbl>, `2006` <dbl>, `2007` <dbl>, `2008` <dbl>,
# `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>, `2013` <dbl>,
# `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>, `2018` <dbl>,
# `2019` <dbl>, `2020` <dbl>, `2021` <dbl>, `2022` <dbl>The dataset has 6 rows and 28 columns. The first column (variable) is the field_of_study, which are the 6 most frequent fields of study for students graduating in 2022.1 The remaining columns show the proportion of degrees awarded in each year from 1996-2022.
-
Your turn (4 minutes): Take a look at the plot we aim to make and sketch the data frame we need to make the plot. Determine what each row and each column of the data frame should be. Hint: We need data to be in columns to map to
aesthetic elements of the plot.Columns:
year,pct,field_of_studyRows: Combination of year and field of study
Confused why we don’t want one row for each year and one column for each field of study? See the appendix.
Pivoting
-
Demo: Pivot the
cornell_degdata frame longer such that each row represents a field of study / year combination andyearandpctage of graduates for that year are columns in the data frame.cornell_deg |> pivot_longer( cols = -field_of_study, names_to = "year", values_to = "pct" )# A tibble: 162 × 3 field_of_study year pct <chr> <chr> <dbl> 1 Computer 1996 0.0421 2 Computer 1997 0.0497 3 Computer 1998 0.0581 4 Computer 1999 0.0716 5 Computer 2000 0.0684 6 Computer 2001 0.0859 7 Computer 2002 0.0745 8 Computer 2003 0.0463 9 Computer 2004 0.0327 10 Computer 2005 0.032 # ℹ 152 more rows
Plotting
-
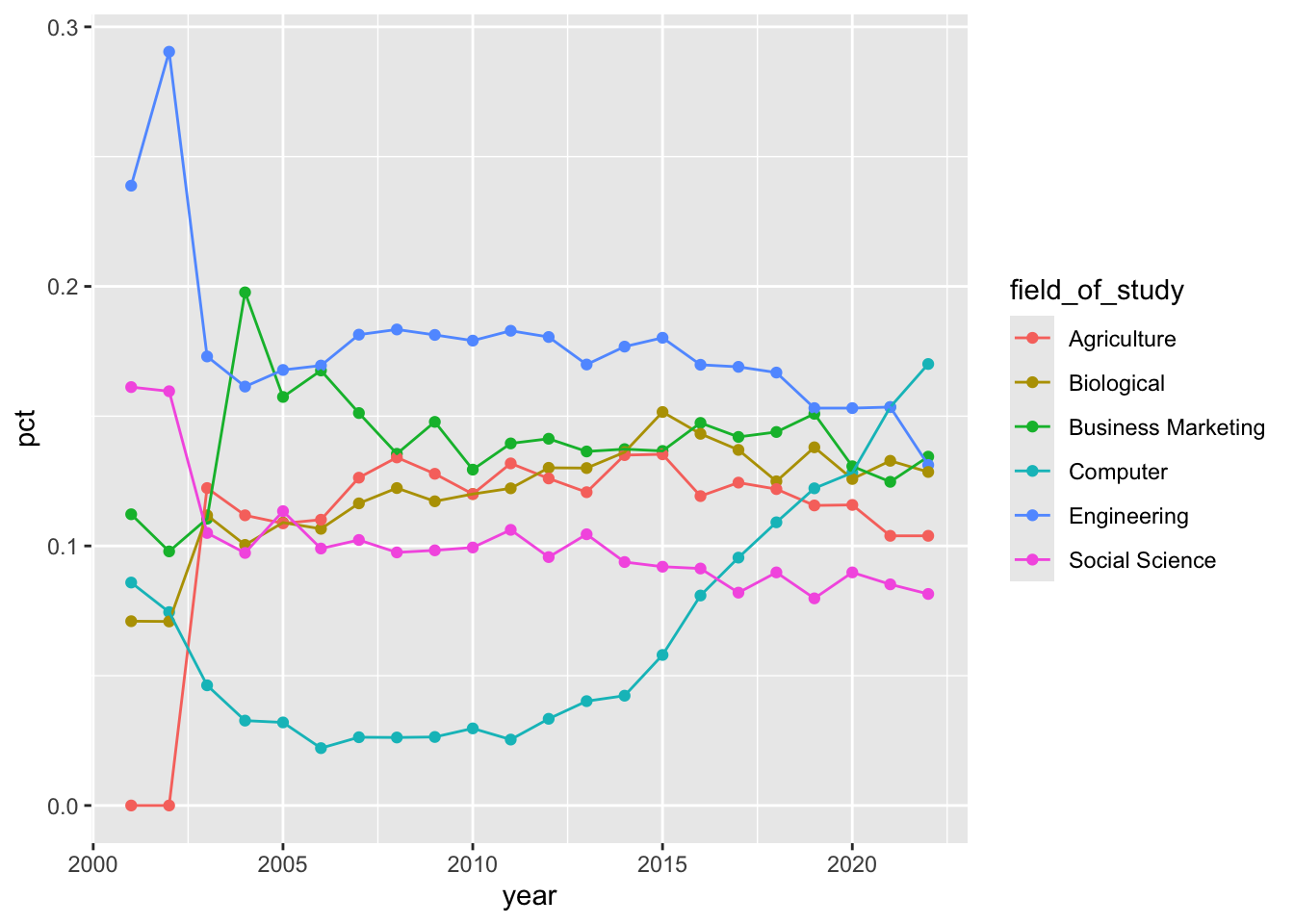
Your turn (5 minutes): Now we start making our plot, but let’s not get too fancy right away. Create the following plot, which will serve as the “first draft” on the way to our Goal. Do this by adding on to your pipeline from earlier.
-
Question: What is the type of the
yearvariable? Why? What should it be?It’s a character (
chr) variable since the information came from the columns of the original data frame and R cannot know that these character strings represent years. The variable type should be numeric. -
Demo: Start over with pivoting, and this time also make sure
yearis a numerical variable in the resulting data frame.cornell_deg |> pivot_longer( cols = -field_of_study, names_to = "year", names_transform = parse_number, values_to = "pct" ) |> ggplot(mapping = aes(x = year, y = pct, color = field_of_study)) + geom_point() + geom_line()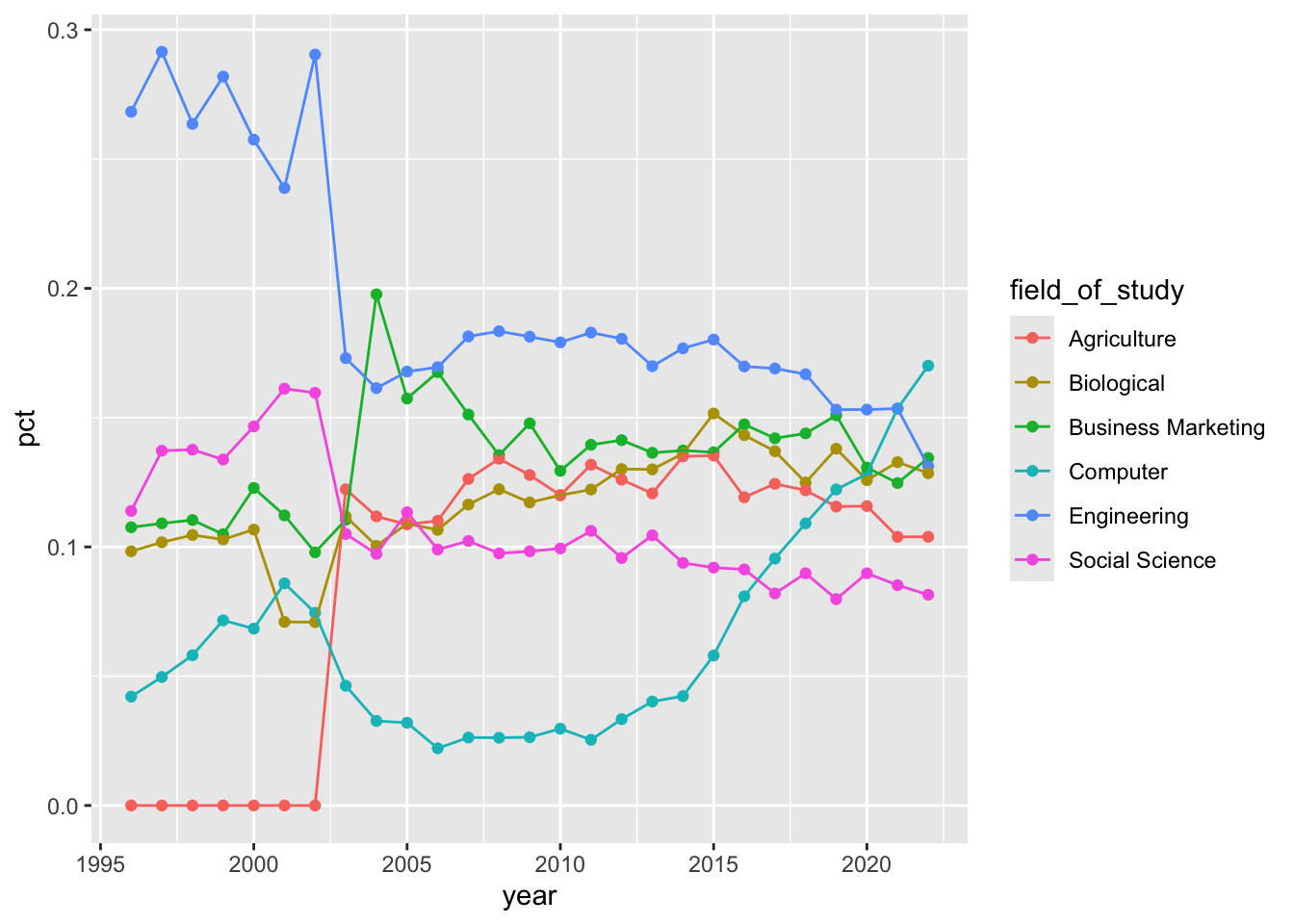
-
Your turn (4 minutes): What aspects of the plot need to be updated to go from the draft you created above to the Goal plot at the beginning of this application exercise.
\(x\)-axis scale: need to go from 1996 to 2022 in increments of 4 years
\(y\)-axis scale: percentage labeling
line colors
axis labels: title, subtitle, \(x\), \(y\), caption
theme
legend: position, order of values, and border
-
Demo: Update the \(x\)-axis scale such that the years displayed go from 1996 to 2022 in increments of 4 years. Update the \(y\)-axis scale so it uses percentage formatting. Do this by adding on to your pipeline from earlier.
cornell_deg |> pivot_longer( cols = -field_of_study, names_to = "year", names_transform = parse_number, values_to = "pct" ) |> ggplot(aes(x = year, y = pct, color = field_of_study)) + geom_point() + geom_line() + scale_x_continuous(limits = c(1996, 2022), breaks = seq(1996, 2020, 4)) + scale_y_continuous(labels = label_percent())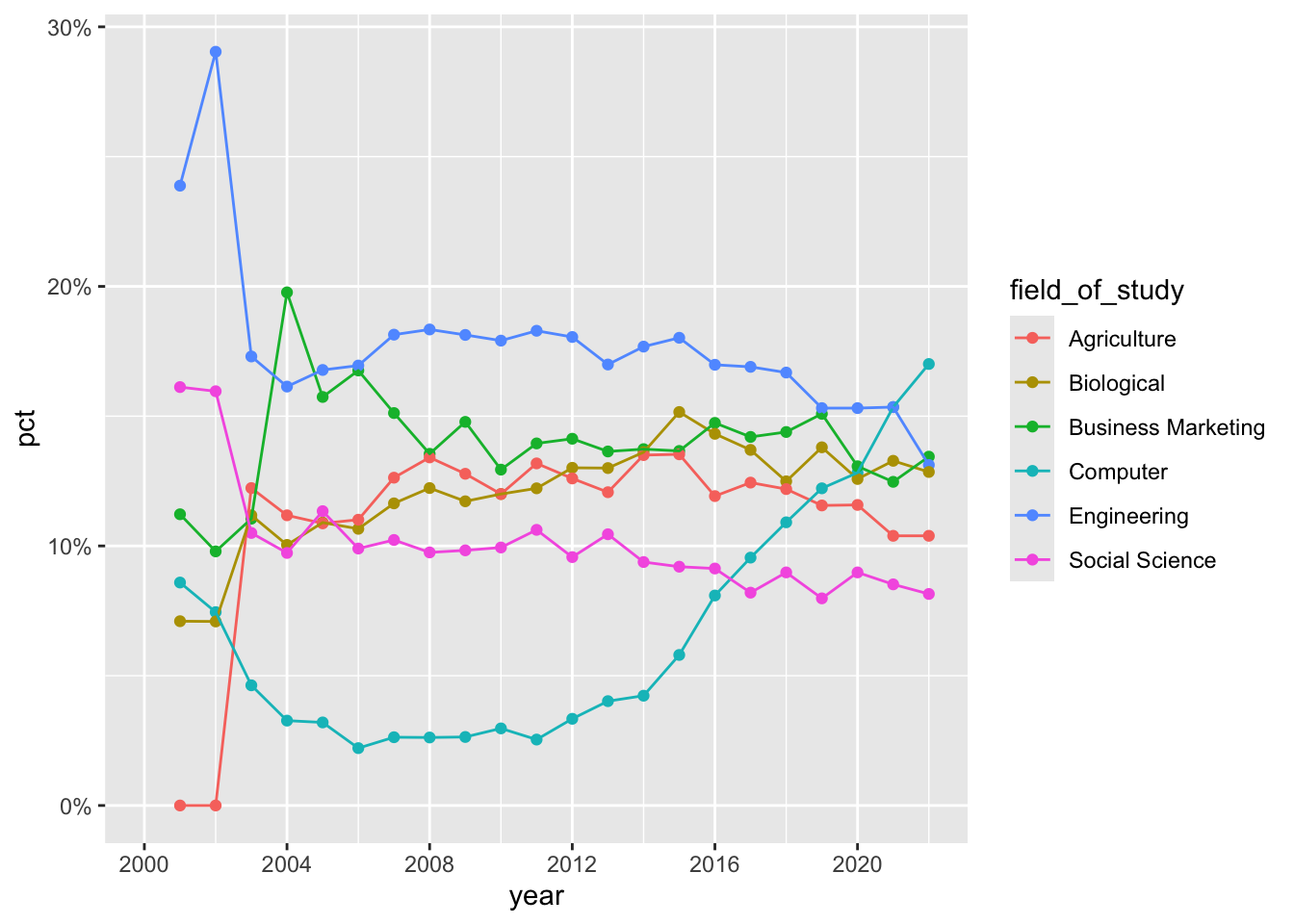
-
Demo: Update the order of the values in the legend so they match the order of the lines in the plot. Do this by adding on to your pipeline from earlier.
cornell_deg |> pivot_longer( cols = -field_of_study, names_to = "year", names_transform = parse_number, values_to = "pct" ) |> mutate( field_of_study = fct_relevel( .f = field_of_study, "Computer", "Business Marketing", "Engineering", "Biological", "Agriculture", "Social Science" ) ) |> ggplot(aes(x = year, y = pct, color = field_of_study)) + geom_point() + geom_line() + scale_x_continuous(limits = c(1996, 2022), breaks = seq(1996, 2020, 4)) + scale_y_continuous(labels = label_percent())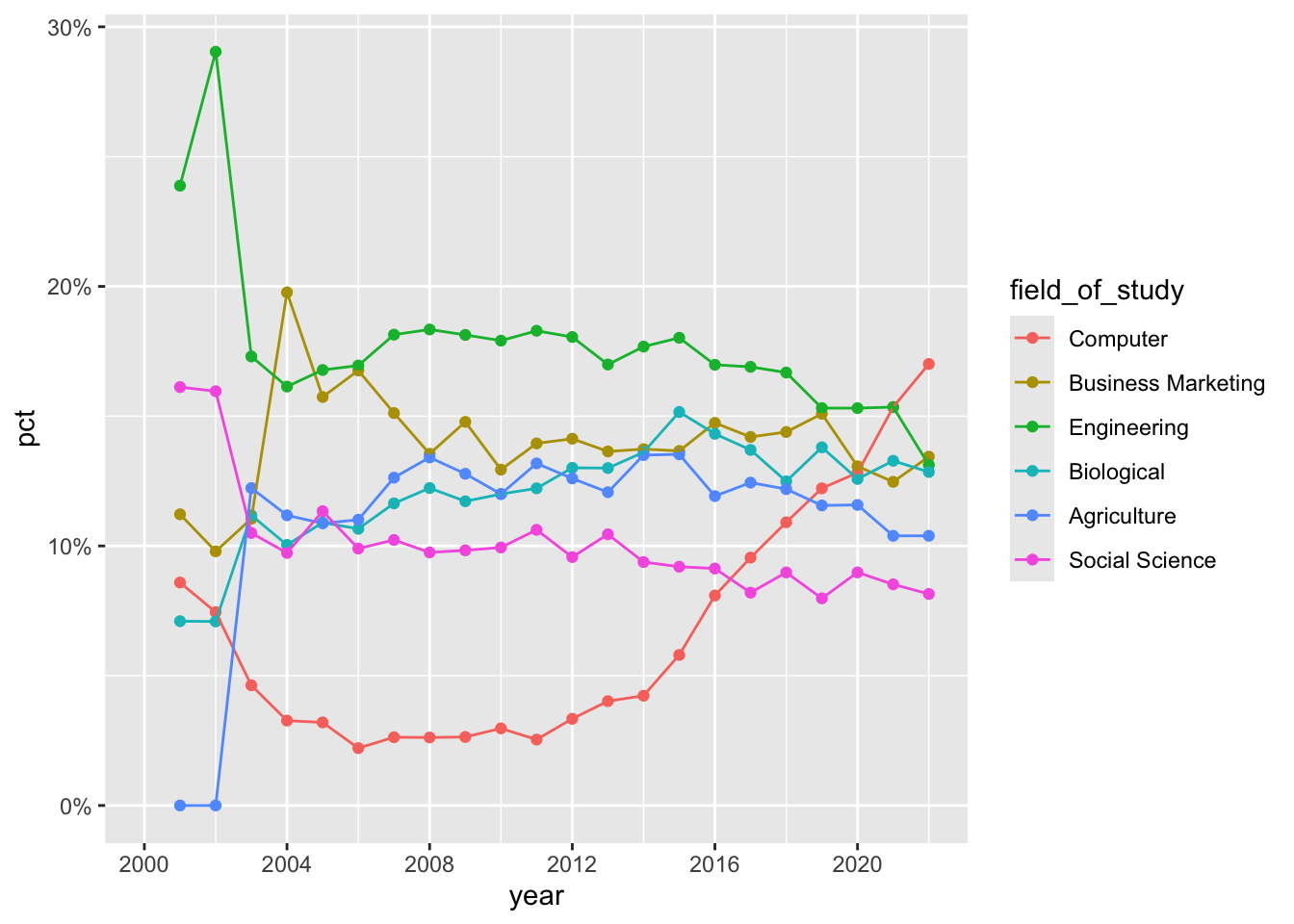 Tip
TipInstead of coding the
field_of_studyvalues manually, you can usefct_reorder2()from the {forcats} package to reorder the levels of a factor based on the values of another variable.field_of_study = fct_reorder2( .f = field_of_study, .x = year, .y = pct )where it reorders the factor by the
.yvalues associated with the largest.xvalues. This ensures the line colors in the legend match up to the end of the lines in the plot. -
Demo: Update line colors using the
scale_color_colorblind()palette from {ggthemes}. Once again, do this by adding on to your pipeline from earlier.library(ggthemes) cornell_deg |> pivot_longer( cols = -field_of_study, names_to = "year", names_transform = parse_number, values_to = "pct" ) |> mutate( field_of_study = fct_relevel( .f = field_of_study, "Computer", "Business Marketing", "Engineering", "Biological", "Agriculture", "Social Science" ) ) |> ggplot(aes(x = year, y = pct, color = field_of_study)) + geom_point() + geom_line() + scale_x_continuous(limits = c(1996, 2022), breaks = seq(1996, 2020, 4)) + scale_y_continuous(labels = label_percent()) + scale_color_colorblind()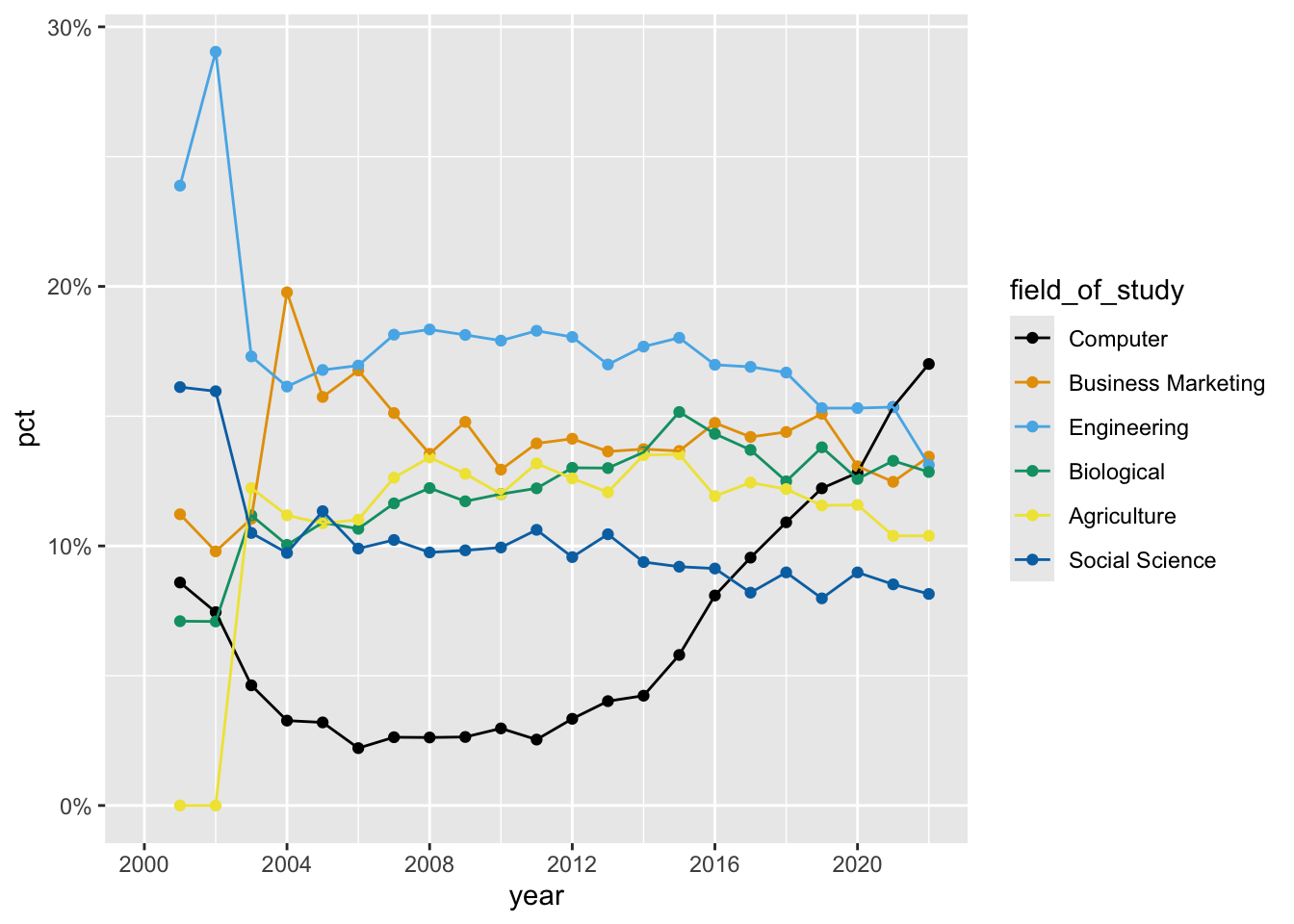
-
Your turn (4 minutes): Update the plot labels (
title,subtitle,x,y, andcaption) and usetheme_minimal(). Once again, do this by adding on to your pipeline from earlier.cornell_deg |> pivot_longer( cols = -field_of_study, names_to = "year", names_transform = parse_number, values_to = "pct" ) |> mutate( field_of_study = fct_relevel( .f = field_of_study, "Computer", "Business Marketing", "Engineering", "Biological", "Agriculture", "Social Science" ) ) |> ggplot(aes(x = year, y = pct, color = field_of_study)) + geom_point() + geom_line() + scale_x_continuous(limits = c(1996, 2022), breaks = seq(1996, 2020, 4)) + scale_color_colorblind() + scale_y_continuous(labels = label_percent()) + labs( x = "Graduation year", y = "Percent of degrees awarded", color = "Field of study", title = "Cornell University degrees awarded from 1996-2022", subtitle = "Only the top six fields as of 2022", caption = "Source: Department of Education\nhttps://collegescorecard.ed.gov/" ) + theme_minimal()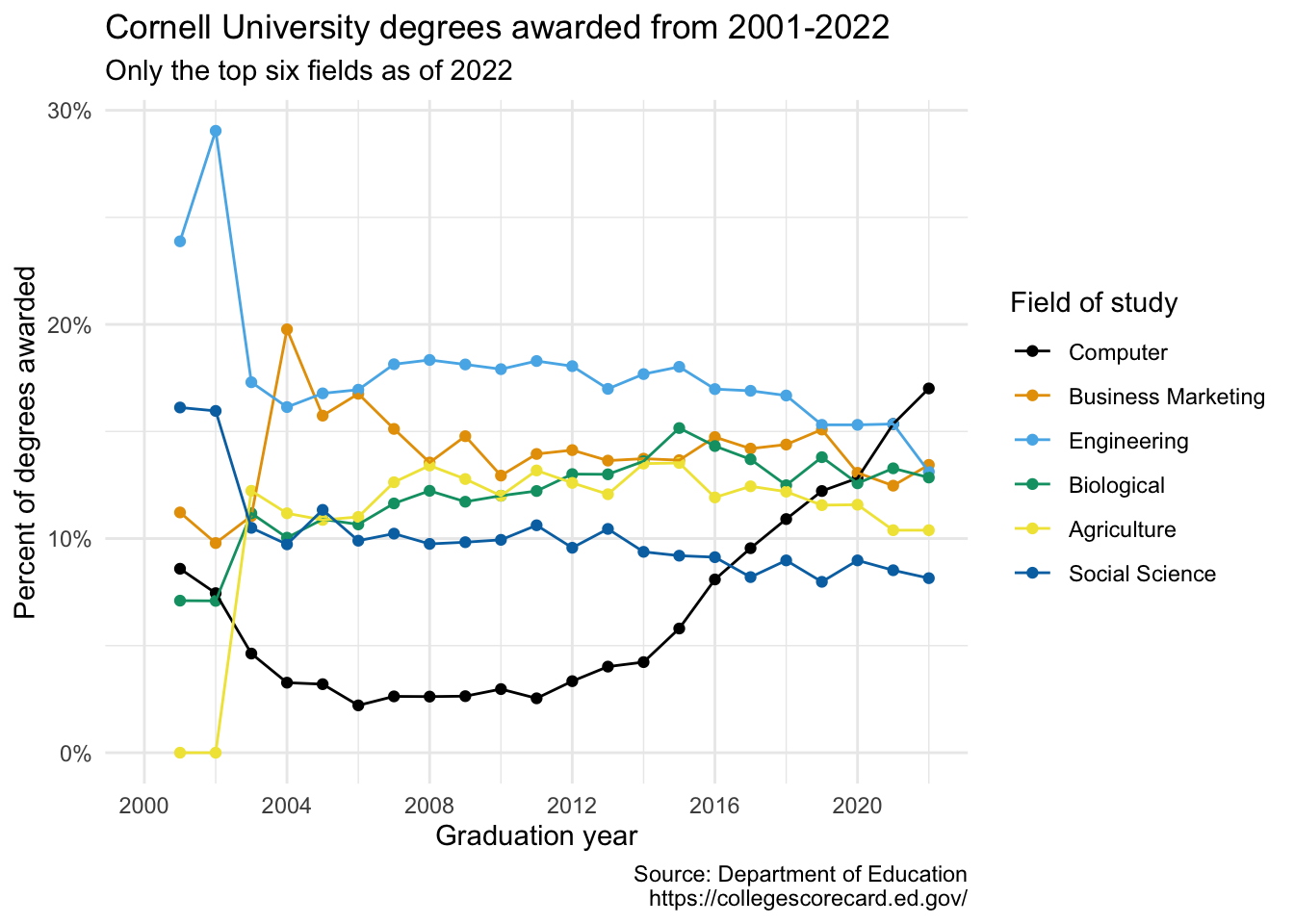
-
Demo: Finally, set
fig-width: 7andfig-height: 5for your plot in the chunk options.```{r} #| label: plot-final #| fig-width: 7 #| fig-height: 5 cornell_deg |> pivot_longer( cols = -field_of_study, names_to = "year", names_transform = parse_number, values_to = "pct" ) |> mutate( field_of_study = fct_relevel( .f = field_of_study, "Computer", "Business Marketing", "Engineering", "Biological", "Agriculture", "Social Science" ) ) |> ggplot(aes(x = year, y = pct, color = field_of_study)) + geom_point() + geom_line() + scale_x_continuous(limits = c(1996, 2022), breaks = seq(1996, 2020, 4)) + scale_color_colorblind() + scale_y_continuous(labels = label_percent()) + labs( x = "Graduation year", y = "Percent of degrees awarded", color = "Field of study", title = "Cornell University degrees awarded from 1996-2022", subtitle = "Only the top six fields as of 2022", caption = "Source: Department of Education\nhttps://collegescorecard.ed.gov/" ) + theme_minimal() ```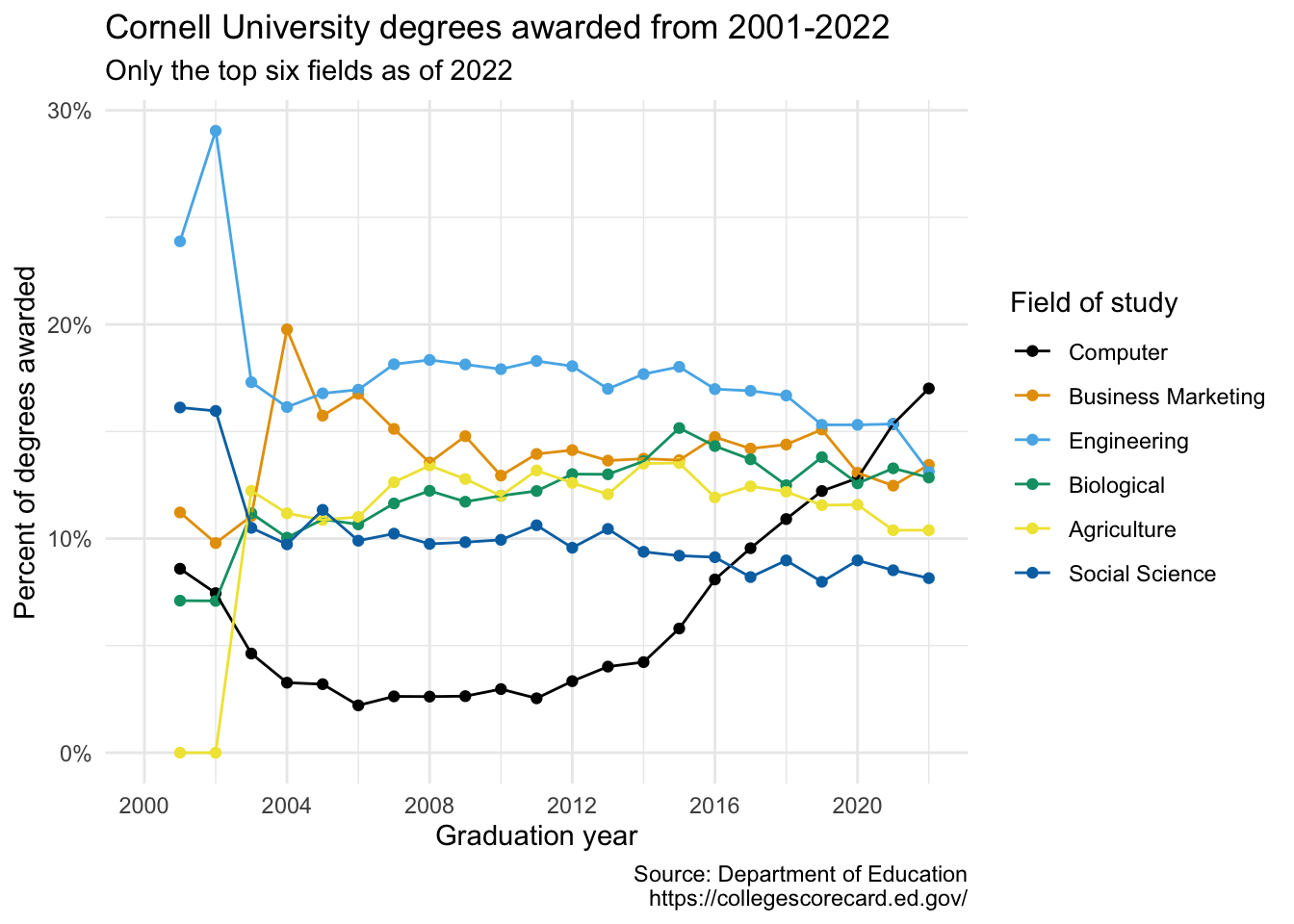
Appendix: Alternative tidying strategy
Another tidying strategy suggested in class was to structure it one row for each year and one column for each of the fields of study. We could do this by transposing the data frame, which requires a pivot_longer() |> pivot_wider() approach:
cornell_deg |>
pivot_longer(
cols = -field_of_study,
names_to = "year",
names_transform = parse_number,
values_to = "pct"
) |>
pivot_wider(
names_from = field_of_study,
values_from = pct
)# A tibble: 27 × 7
year Computer `Business Marketing` Engineering Biological Agriculture
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1996 0.0421 0.108 0.268 0.0983 0
2 1997 0.0497 0.109 0.292 0.102 0
3 1998 0.0581 0.110 0.264 0.105 0
4 1999 0.0716 0.105 0.282 0.103 0
5 2000 0.0684 0.123 0.258 0.107 0
6 2001 0.0859 0.112 0.239 0.071 0
7 2002 0.0745 0.0979 0.290 0.0709 0
8 2003 0.0463 0.110 0.173 0.112 0.122
9 2004 0.0327 0.198 0.161 0.100 0.112
10 2005 0.032 0.157 0.168 0.109 0.109
# ℹ 17 more rows
# ℹ 1 more variable: `Social Science` <dbl>But now we need to construct the line graph with the percentages spread across six columns. It would require us writing a separate geom_*() function for each field of study:
cornell_deg |>
pivot_longer(
cols = -field_of_study,
names_to = "year",
names_transform = parse_number,
values_to = "pct"
) |>
pivot_wider(
names_from = field_of_study,
values_from = pct
) |>
ggplot(aes(x = year)) +
geom_point(mapping = aes(y = Computer)) +
geom_line(mapping = aes(y = Computer)) +
geom_point(mapping = aes(y = Engineering)) +
geom_line(mapping = aes(y = Engineering)) +
geom_point(mapping = aes(y = Biological)) +
geom_line(mapping = aes(y = Biological)) +
geom_point(mapping = aes(y = `Business Marketing`)) +
geom_line(mapping = aes(y = `Business Marketing`)) +
geom_point(mapping = aes(y = Agriculture)) +
geom_line(mapping = aes(y = Agriculture)) +
geom_point(mapping = aes(y = `Social Science`)) +
geom_line(mapping = aes(y = `Social Science`))![]()
And we still don’t have color-coding. We could use the colorargument in each geom_*() function to change the color of each layer.
cornell_deg |>
pivot_longer(
cols = -field_of_study,
names_to = "year",
names_transform = parse_number,
values_to = "pct"
) |>
pivot_wider(
names_from = field_of_study,
values_from = pct
) |>
ggplot(aes(x = year)) +
geom_point(mapping = aes(y = Computer), color = "black") +
geom_line(mapping = aes(y = Computer), color = "black") +
geom_point(mapping = aes(y = Engineering), color = "orange") +
geom_line(mapping = aes(y = Engineering), color = "orange") +
geom_point(mapping = aes(y = Biological), color = "lightblue") +
geom_line(mapping = aes(y = Biological), color = "lightblue") +
geom_point(mapping = aes(y = `Business Marketing`), color = "green") +
geom_line(mapping = aes(y = `Business Marketing`), color = "green") +
geom_point(mapping = aes(y = Agriculture), color = "yellow") +
geom_line(mapping = aes(y = Agriculture), color = "yellow") +
geom_point(mapping = aes(y = `Social Science`), color = "darkblue") +
geom_line(mapping = aes(y = `Social Science`), color = "darkblue")![]()
But we still do not have a legend that tells us what each color represents. We want a legend generated automatically and that only happens if we map something to the color channel using aes(). We can hack this a bit by passing a character string within aes() to define a different unique value for each layer.
cornell_deg |>
pivot_longer(
cols = -field_of_study,
names_to = "year",
names_transform = parse_number,
values_to = "pct"
) |>
pivot_wider(
names_from = field_of_study,
values_from = pct
) |>
ggplot(aes(x = year)) +
geom_point(mapping = aes(y = Computer, color = "Computer")) +
geom_line(mapping = aes(y = Computer, color = "Computer")) +
geom_point(mapping = aes(y = Engineering, color = "Engineering")) +
geom_line(mapping = aes(y = Engineering, color = "Engineering")) +
geom_point(mapping = aes(y = Biological, color = "Biological")) +
geom_line(mapping = aes(y = Biological, color = "Biological")) +
geom_point(mapping = aes(y = `Business Marketing`, color = "Business Marketing")) +
geom_line(mapping = aes(y = `Business Marketing`, color = "Business Marketing")) +
geom_point(mapping = aes(y = Agriculture, color = "Agriculture")) +
geom_line(mapping = aes(y = Agriculture, color = "Agriculture")) +
geom_point(mapping = aes(y = `Social Science`, color = "Social Science")) +
geom_line(mapping = aes(y = `Social Science`, color = "Social Science"))![]()
Polished up we get the same plot.
cornell_deg |>
pivot_longer(
cols = -field_of_study,
names_to = "year",
names_transform = parse_number,
values_to = "pct"
) |>
pivot_wider(
names_from = field_of_study,
values_from = pct
) |>
ggplot(aes(x = year)) +
geom_point(mapping = aes(y = Computer, color = "Computer")) +
geom_line(mapping = aes(y = Computer, color = "Computer")) +
geom_point(mapping = aes(y = Engineering, color = "Engineering")) +
geom_line(mapping = aes(y = Engineering, color = "Engineering")) +
geom_point(mapping = aes(y = Biological, color = "Biological")) +
geom_line(mapping = aes(y = Biological, color = "Biological")) +
geom_point(mapping = aes(y = `Business Marketing`, color = "Business Marketing")) +
geom_line(mapping = aes(y = `Business Marketing`, color = "Business Marketing")) +
geom_point(mapping = aes(y = Agriculture, color = "Agriculture")) +
geom_line(mapping = aes(y = Agriculture, color = "Agriculture")) +
geom_point(mapping = aes(y = `Social Science`, color = "Social Science")) +
geom_line(mapping = aes(y = `Social Science`, color = "Social Science")) +
scale_x_continuous(limits = c(1996, 2022), breaks = seq(1996, 2020, 4)) +
scale_color_colorblind(breaks = c(
"Computer", "Business Marketing", "Engineering",
"Biological", "Agriculture", "Social Science"
)) +
scale_y_continuous(labels = label_percent()) +
labs(
x = "Graduation year",
y = "Percent of degrees awarded",
color = "Field of study",
title = "Cornell University degrees awarded from 1996-2022",
subtitle = "Only the top six fields as of 2022",
caption = "Source: Department of Education\nhttps://collegescorecard.ed.gov/"
) +
theme_minimal()![]()
But with a lot more effort.
Acknowledgments
- This assignment is inspired by STA 199: Introduction to Data Science
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.5.1 (2025-06-13)
os macOS Sequoia 15.6.1
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/New_York
date 2025-09-12
pandoc 3.6.3 @ /Applications/Positron.app/Contents/Resources/app/quarto/bin/tools/aarch64/ (via rmarkdown)
quarto 1.8.24 @ /Applications/quarto/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
! package * version date (UTC) lib source
P bit 4.6.0 2025-03-06 [?] RSPM (R 4.5.0)
P bit64 4.6.0-1 2025-01-16 [?] RSPM (R 4.5.0)
P cli 3.6.5 2025-04-23 [?] RSPM (R 4.5.0)
P crayon 1.5.3 2024-06-20 [?] RSPM (R 4.5.0)
P digest 0.6.37 2024-08-19 [?] RSPM (R 4.5.0)
P dplyr * 1.1.4 2023-11-17 [?] RSPM (R 4.5.0)
P evaluate 1.0.4 2025-06-18 [?] RSPM (R 4.5.0)
P farver 2.1.2 2024-05-13 [?] RSPM (R 4.5.0)
P fastmap 1.2.0 2024-05-15 [?] RSPM (R 4.5.0)
P forcats * 1.0.0 2023-01-29 [?] RSPM (R 4.5.0)
P generics 0.1.4 2025-05-09 [?] RSPM (R 4.5.0)
P ggplot2 * 3.5.2 2025-04-09 [?] RSPM (R 4.5.0)
P ggthemes * 5.1.0 2024-02-10 [?] RSPM
P glue 1.8.0 2024-09-30 [?] RSPM (R 4.5.0)
P gtable 0.3.6 2024-10-25 [?] RSPM (R 4.5.0)
P here 1.0.1 2020-12-13 [?] RSPM (R 4.5.0)
P hms 1.1.3 2023-03-21 [?] RSPM (R 4.5.0)
P htmltools 0.5.8.1 2024-04-04 [?] RSPM (R 4.5.0)
P htmlwidgets 1.6.4 2023-12-06 [?] RSPM (R 4.5.0)
P jsonlite 2.0.0 2025-03-27 [?] RSPM (R 4.5.0)
P knitr 1.50 2025-03-16 [?] RSPM (R 4.5.0)
P labeling 0.4.3 2023-08-29 [?] RSPM (R 4.5.0)
P lifecycle 1.0.4 2023-11-07 [?] RSPM (R 4.5.0)
P lubridate * 1.9.4 2024-12-08 [?] RSPM (R 4.5.0)
P magrittr 2.0.3 2022-03-30 [?] RSPM (R 4.5.0)
P pillar 1.11.0 2025-07-04 [?] RSPM (R 4.5.0)
P pkgconfig 2.0.3 2019-09-22 [?] RSPM (R 4.5.0)
P purrr * 1.1.0 2025-07-10 [?] RSPM (R 4.5.0)
P R6 2.6.1 2025-02-15 [?] RSPM (R 4.5.0)
P ragg 1.4.0 2025-04-10 [?] RSPM (R 4.5.0)
P RColorBrewer 1.1-3 2022-04-03 [?] RSPM (R 4.5.0)
P readr * 2.1.5 2024-01-10 [?] RSPM (R 4.5.0)
renv 1.0.7 2024-04-11 [1] RSPM (R 4.5.1)
P rlang 1.1.6 2025-04-11 [?] RSPM (R 4.5.0)
P rmarkdown 2.29 2024-11-04 [?] RSPM (R 4.5.0)
P rprojroot 2.1.0 2025-07-12 [?] RSPM (R 4.5.0)
P scales * 1.4.0 2025-04-24 [?] RSPM (R 4.5.0)
P sessioninfo 1.2.3 2025-02-05 [?] RSPM (R 4.5.0)
P stringi 1.8.7 2025-03-27 [?] RSPM (R 4.5.0)
P stringr * 1.5.1 2023-11-14 [?] RSPM (R 4.5.0)
P systemfonts 1.2.3 2025-04-30 [?] RSPM (R 4.5.0)
P textshaping 1.0.1 2025-05-01 [?] RSPM (R 4.5.0)
P tibble * 3.3.0 2025-06-08 [?] RSPM (R 4.5.0)
P tidyr * 1.3.1 2024-01-24 [?] RSPM (R 4.5.0)
P tidyselect 1.2.1 2024-03-11 [?] RSPM (R 4.5.0)
P tidyverse * 2.0.0 2023-02-22 [?] RSPM (R 4.5.0)
P timechange 0.3.0 2024-01-18 [?] RSPM (R 4.5.0)
P tzdb 0.5.0 2025-03-15 [?] RSPM (R 4.5.0)
P utf8 1.2.6 2025-06-08 [?] RSPM (R 4.5.0)
P vctrs 0.6.5 2023-12-01 [?] RSPM (R 4.5.0)
P vroom 1.6.5 2023-12-05 [?] RSPM (R 4.5.0)
P withr 3.0.2 2024-10-28 [?] RSPM (R 4.5.0)
P xfun 0.52 2025-04-02 [?] RSPM (R 4.5.0)
P yaml 2.3.10 2024-07-26 [?] RSPM (R 4.5.0)
[1] /Users/bcs88/Projects/info-5001/course-site/renv/library/macos/R-4.5/aarch64-apple-darwin20
[2] /Users/bcs88/Library/Caches/org.R-project.R/R/renv/sandbox/macos/R-4.5/aarch64-apple-darwin20/4cd76b74
* ── Packages attached to the search path.
P ── Loaded and on-disk path mismatch.
──────────────────────────────────────────────────────────────────────────────Footnotes
For the sake of application, I omitted the other 32 possible fields of study.↩︎