AE 07: Data wrangling with rowwise/column-wise operations
Some chunks require you to merely fill in the TODOs with the appropriate code. Other chunks require you to write the entire code block.
Packages
We will use the following packages in this application exercise.
- tidyverse: For data import, wrangling, and visualization.
- janitor: For cleaning column names.
Powerball
Last class we studied Powerball jackpots over time. Today we will continue this journey and focus on Colorado winners in Match \(N\) Powerball play, prizes available to players who match the red Powerball number and anywhere between 0-4 white ball numbers.
Import and clean the data
The dataset is available for download as a CSV file.
Demo: Import the data file. Store it as powerball_raw.
powerball_raw <- read_csv(file = "data/POWERBALL-from_0001-01-01_to_2024-09-24.csv")
powerball_rawYour turn: Clean the raw data to fix the following issues:
- Standardize the column names using
snake_caseformat. - Create columns with appropriate data types for any date variables date of the drawing as well as the weekday. Append these columns to the beginning of the data frame.
- Fix all of the currency columns to be formatted as numeric types.
Store the cleaned data frame as powerball.
powerball <- powerball_raw |>
clean_names() |>
# separate draw_date into two variables, clean both
separate_wider_delim(
cols = draw_date,
delim = ",",
names = c(NA, "draw_date")
) |>
mutate(
draw_date = mdy(draw_date),
last_day_to_claim = mdy(last_day_to_claim),
draw_weekday = wday(x = draw_date, label = TRUE),
.before = last_day_to_claim
) |>
# convert all currency columns to numeric type
mutate(
across(
.cols = TODO,
.fn = parse_number
)
)Analyze the data
Our goal is to reproduce the following visualization:
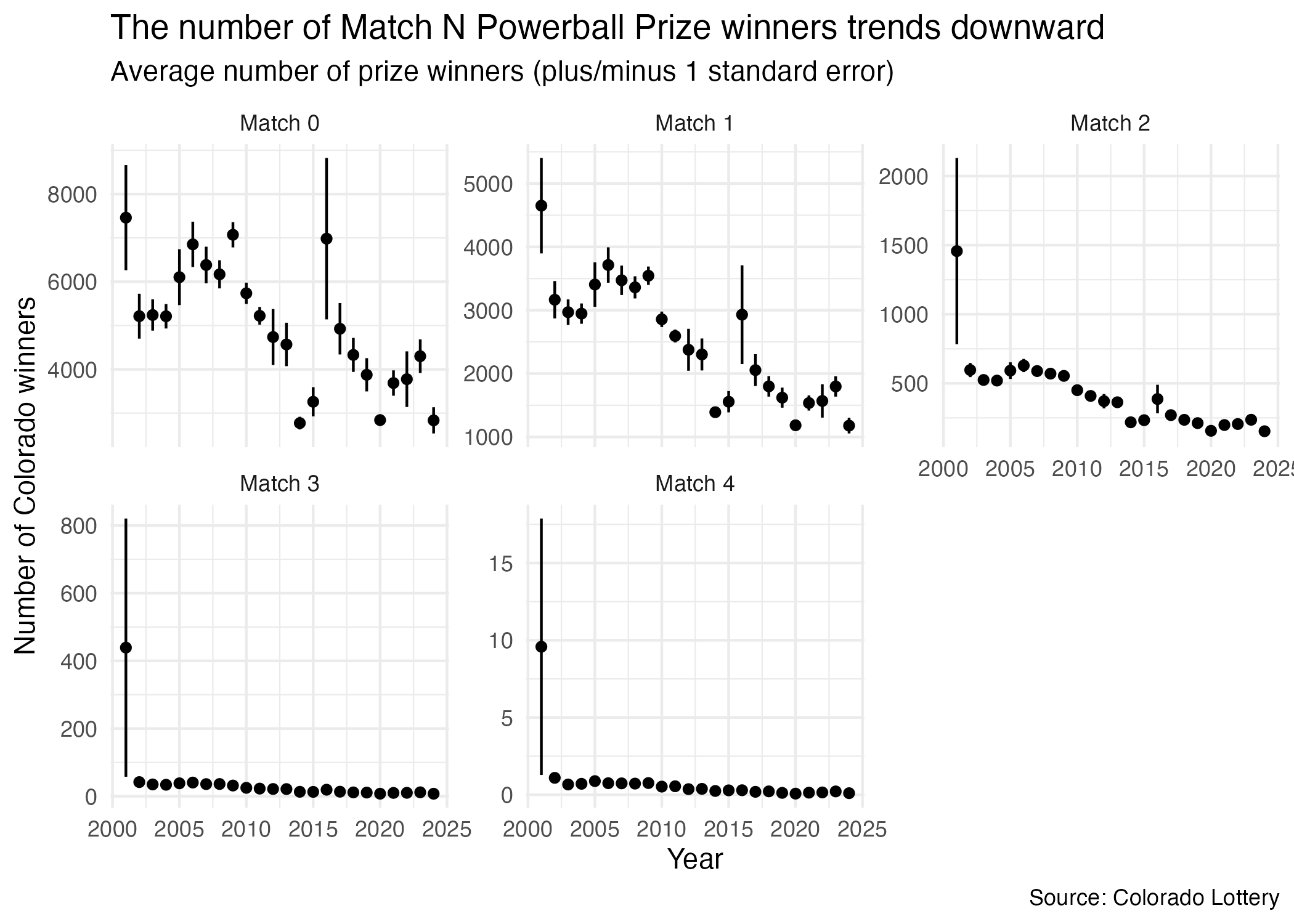
In order to accomplish this, we have a few challenges ahead. We will need to:
- Determine the year for every drawing
- Calculate the mean and standard error of the number of winners for each Match \(N\) + Powerball prize for every year
- Structure the data frame so we have one row for each year and prize, and separate columns for the means and standard errors
Generate the year variable
Your turn: Generate a year variable from the draw_date column.
# add code here
powerball |>
# generate year variable
mutate(
year = TODO,
.before = everything()
)Calculate means and standard errors
Your turn: Calculate the mean and standard error for each of the number of winners of the Match \(N\) + Powerball prizes for each year. Your data frame should look something like this:
# A tibble: 24 × 11
year match_4_powerball_co_winners_m…¹ match_4_powerball_co…² match_3_powerball_co…³ match_3_powerball_co…⁴ match_2_powerball_co…⁵
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2024 0.104 0.0286 7.39 0.834 153.
2 2023 0.218 0.0475 11.6 1.15 236.
3 2022 0.153 0.0363 10.1 1.66 205.
4 2021 0.138 0.0312 9.88 0.804 198.
5 2020 0.0762 0.0260 7.49 0.481 156.
6 2019 0.125 0.0326 10.8 1.18 212.
7 2018 0.221 0.0510 11.3 1.04 236.
8 2017 0.192 0.0412 13.4 1.89 270.
9 2016 0.295 0.103 19.2 5.47 386.
10 2015 0.288 0.0839 12.9 1.55 233.
# ℹ 14 more rows
# ℹ abbreviated names: ¹match_4_powerball_co_winners_mean, ²match_4_powerball_co_winners_se, ³match_3_powerball_co_winners_mean,
# ⁴match_3_powerball_co_winners_se, ⁵match_2_powerball_co_winners_mean
# ℹ 5 more variables: match_2_powerball_co_winners_se <dbl>, match_1_powerball_co_winners_mean <dbl>,
# match_1_powerball_co_winners_se <dbl>, match_0_powerball_co_winners_mean <dbl>, match_0_powerball_co_winners_se <dbl>
# ℹ Use `print(n = ...)` to see more rowsRecall the formula for the standard error of a sample mean is:
\[ \begin{aligned} \text{s.e.} &= \sqrt{\frac{\text{Variance}(X)}{\text{Sample size}}} \\ &= \frac{\text{Standard deviation}(X)}{\sqrt{\text{Sample size}}} \end{aligned} \]
# add code here
powerball |>
# generate year variable
mutate(
year = TODO,
.before = everything()
) |>
# calculate mean and se for the match N powerball winner columns
summarize(
across(
.cols = TODO,
.fns = list(mean = mean, se = TODO)
),
# do this for each year in the dataset
.by = year
)Clean up column names
Your turn: Remove "powerball_co_winners_" from each column name.
rename() does not allow use of the across() function. Instead, check out rename_with() from the dplyr package.
stringr contains many functions for working with character strings. Check out the cheat sheet for examples!
# add code here
powerball |>
# generate year variable
mutate(
year = TODO,
.before = everything()
) |>
# calculate mean and se for the match N powerball winner columns
summarize(
across(
.cols = TODO,
.fns = list(mean = mean, se = TODO)
),
# do this for each year in the dataset
.by = year
) |>
# remove extraneous string from columns
rename_with(
.cols = TODO,
.fn = \(x) str_TODO(string = x, pattern = "powerball_co_winners_")
)Restructure data frame to appropriate form for visualization
Demo: We need the structure to be one row for each year and prize (i.e. 0, 1, 2, 3, 4) and separate columns for the means and standard errors. We can use pivot_longer() to accomplish this task, but it’s a bit more complicated than past pivoting operations since the column names contain both a variable (e.g. match_4) and a variable name (i.e. mean or se).
# add code here
powerball_stats <- powerball |>
# generate year variable
mutate(
year = TODO,
.before = everything()
) |>
# calculate mean and se for the match N powerball winner columns
summarize(
across(
.cols = TODO,
.fns = list(mean = mean, se = TODO)
),
# do this for each year in the dataset
.by = year
) |>
# remove extraneous string from columns
rename_with(
.cols = TODO,
.fn = \(x) str_TODO(string = x, pattern = "powerball_co_winners_")
) |>
# restructure to one row per year per game
# separate columns for mean and se
pivot_longer(
cols = -year,
# columns contain a variable and a variable name
names_to = c("game", ".value"),
# ignore column prefix
names_prefix = "match_",
# separating character
names_sep = "_"
) |>
# reformat game column values for visualization
mutate(game = str_glue("Match {game}"))
powerball_statsPlot the data
Demo: Now that we have the appropriate data structure, we can create the visualization.
ggplot(data = powerball_stats, mapping = aes(x = year, y = mean)) +
geom_point() +
geom_linerange(mapping = aes(
ymin = mean - se,
ymax = mean + se
)) +
facet_wrap(facets = vars(game), scales = "free_y") +
labs(
title = "The number of Match N Powerball Prize winners trends downward",
subtitle = "Average number of prize winners (plus/minus 1 standard error)",
x = "Year",
y = "Number of Colorado winners",
caption = "Source: Colorado Lottery"
) +
theme_minimal()