Obtaining World Bank indicators
The World Bank contains a rich and detailed set of socioeconomic indicators spanning several decades and dozens of topics. Their data is available for bulk download as CSV files from their website. However, frequently you only need to obtain a handful of indicators or a subset of countries.
To provide more granular access to this information, the World Bank provides a RESTful API for querying and obtaining a portion of their database programmatically. The wbstats implements this API in R to allow for relatively easy access to the API and return the results in a tidy data frame.
Finding available data with wb_cachelist
wb_cachelist contains a snapshot of available countries, indicators, and other relevant information obtainable through the WB API.
List of 8
$ countries : tibble [304 × 18] (S3: tbl_df/tbl/data.frame)
$ indicators : tibble [16,649 × 8] (S3: tbl_df/tbl/data.frame)
$ sources : tibble [63 × 9] (S3: tbl_df/tbl/data.frame)
$ topics : tibble [21 × 3] (S3: tbl_df/tbl/data.frame)
$ regions : tibble [48 × 4] (S3: tbl_df/tbl/data.frame)
$ income_levels: tibble [7 × 3] (S3: tbl_df/tbl/data.frame)
$ lending_types: tibble [4 × 3] (S3: tbl_df/tbl/data.frame)
$ languages : tibble [23 × 3] (S3: tbl_df/tbl/data.frame)glimpse(wb_cachelist$countries)Rows: 304
Columns: 18
$ iso3c <chr> "ABW", "AFG", "AFR", "AGO", "ALB", "AND", "ANR", "A…
$ iso2c <chr> "AW", "AF", "A9", "AO", "AL", "AD", "L5", "1A", "AE…
$ country <chr> "Aruba", "Afghanistan", "Africa", "Angola", "Albani…
$ capital_city <chr> "Oranjestad", "Kabul", NA, "Luanda", "Tirane", "And…
$ longitude <dbl> -70.01670, 69.17610, NA, 13.24200, 19.81720, 1.5218…
$ latitude <dbl> 12.51670, 34.52280, NA, -8.81155, 41.33170, 42.5075…
$ region_iso3c <chr> "LCN", "SAS", NA, "SSF", "ECS", "ECS", NA, NA, "MEA…
$ region_iso2c <chr> "ZJ", "8S", NA, "ZG", "Z7", "Z7", NA, NA, "ZQ", "ZJ…
$ region <chr> "Latin America & Caribbean", "South Asia", "Aggrega…
$ admin_region_iso3c <chr> NA, "SAS", NA, "SSA", "ECA", NA, NA, NA, NA, "LAC",…
$ admin_region_iso2c <chr> NA, "8S", NA, "ZF", "7E", NA, NA, NA, NA, "XJ", "7E…
$ admin_region <chr> NA, "South Asia", NA, "Sub-Saharan Africa (excludin…
$ income_level_iso3c <chr> "HIC", "LIC", NA, "LMC", "UMC", "HIC", NA, NA, "HIC…
$ income_level_iso2c <chr> "XD", "XM", NA, "XN", "XT", "XD", NA, NA, "XD", "XT…
$ income_level <chr> "High income", "Low income", "Aggregates", "Lower m…
$ lending_type_iso3c <chr> "LNX", "IDX", NA, "IBD", "IBD", "LNX", NA, NA, "LNX…
$ lending_type_iso2c <chr> "XX", "XI", NA, "XF", "XF", "XX", NA, NA, "XX", "XF…
$ lending_type <chr> "Not classified", "IDA", "Aggregates", "IBRD", "IBR…Search available data with wb_search()
wb_search() searches through the wb_cachelist$indicators data frame to find indicators that match the search pattern.1
wb_search("unemployment")# A tibble: 61 × 3
indicator_id indicator indicator_desc
<chr> <chr> <chr>
1 fin37.t.a Received government transfers in the past year (… The percentag…
2 fin37.t.a.1 Received government transfers in the past year, … The percentag…
3 fin37.t.a.10 Received government transfers in the past year, … The percentag…
4 fin37.t.a.11 Received government transfers in the past year, … The percentag…
5 fin37.t.a.2 Received government transfers in the past year, … The percentag…
6 fin37.t.a.3 Received government transfers in the past year, … The percentag…
7 fin37.t.a.4 Received government transfers in the past year, … The percentag…
8 fin37.t.a.5 Received government transfers in the past year, … The percentag…
9 fin37.t.a.6 Received government transfers in the past year, … The percentag…
10 fin37.t.a.7 Received government transfers in the past year, … The percentag…
# ℹ 51 more rowswb_search("labor force")# A tibble: 245 × 3
indicator_id indicator indicator_desc
<chr> <chr> <chr>
1 9.0.Employee.All Employees (%) Share of the …
2 9.0.Employee.B40 Employees-Bottom 40 Percent (%) Share of the …
3 9.0.Employee.T60 Employees-Top 60 Percent (%) Share of the …
4 9.0.Employer.All Employers (%) Share of the …
5 9.0.Employer.B40 Employers-Bottom 40 Percent (%) Share of the …
6 9.0.Employer.T60 Employers-Top 60 Percent (%) Share of the …
7 9.0.Labor.All Labor Force Participation Rate (%) Share of the …
8 9.0.Labor.B40 Labor Force Participation Rate (%)-Bottom 40… Share of the …
9 9.0.Labor.T60 Labor Force Participation Rate (%)-Top 60 Pe… Share of the …
10 9.0.SelfEmp.All Self-Employed (%) Share of the …
# ℹ 235 more rowswb_search("labor force", fields = "indicator") # limit search to just the indicator name# A tibble: 176 × 3
indicator_id indicator indicator_desc
<chr> <chr> <chr>
1 9.0.Labor.All Labor Force Participation Rate (%) Share of the …
2 9.0.Labor.B40 Labor Force Participation Rate (%)-Bottom 40 P… Share of the …
3 9.0.Labor.T60 Labor Force Participation Rate (%)-Top 60 Perc… Share of the …
4 9.1.Labor.All Labor Force Participation Rate (%), Male Share of the …
5 9.1.Labor.B40 Labor Force Participation Rate (%)-Bottom 40 P… Share of the …
6 9.1.Labor.T60 Labor Force Participation Rate (%)-Top 60 Perc… Share of the …
7 9.2.Labor.All Labor Force Participation Rate (%), Female Share of the …
8 9.2.Labor.B40 Labor Force Participation Rate (%)-Bottom 40 P… Share of the …
9 9.2.Labor.T60 Labor Force Participation Rate (%)-Top 60 Perc… Share of the …
10 account.t.d.10 Account, in labor force (% age 15+) The percentag…
# ℹ 166 more rowsDownloading data with wb_data()
Once you have the set of indicators you would like to obtain, you can use the wb_data() function to generate the API query and download the results. Let’s say we want to obtain information on the percent of females participating in the labor force. The indicator ID is SL.TLF.TOTL.FE.ZS. We can download the indicator for all countries from 1990-2022 using:
female_labor <- wb_data(
indicator = "SL.TLF.TOTL.FE.ZS",
start_date = 1990,
end_date = 2022
)
female_labor# A tibble: 7,161 × 9
iso2c iso3c country date SL.TLF.TOTL.FE.ZS unit obs_status footnote
<chr> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr>
1 AW ABW Aruba 1990 NA <NA> <NA> <NA>
2 AW ABW Aruba 1991 NA <NA> <NA> <NA>
3 AW ABW Aruba 1992 NA <NA> <NA> <NA>
4 AW ABW Aruba 1993 NA <NA> <NA> <NA>
5 AW ABW Aruba 1994 NA <NA> <NA> <NA>
6 AW ABW Aruba 1995 NA <NA> <NA> <NA>
7 AW ABW Aruba 1996 NA <NA> <NA> <NA>
8 AW ABW Aruba 1997 NA <NA> <NA> <NA>
9 AW ABW Aruba 1998 NA <NA> <NA> <NA>
10 AW ABW Aruba 1999 NA <NA> <NA> <NA>
# ℹ 7,151 more rows
# ℹ 1 more variable: last_updated <date>Note the column containing our indicator uses the indicator ID as its name. This is rather un-intuitive, so we can adjust it directly in the function.
# A tibble: 7,161 × 9
iso2c iso3c country date fem_lab_part unit obs_status footnote last_updated
<chr> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr> <date>
1 AW ABW Aruba 1990 NA <NA> <NA> <NA> 2024-09-19
2 AW ABW Aruba 1991 NA <NA> <NA> <NA> 2024-09-19
3 AW ABW Aruba 1992 NA <NA> <NA> <NA> 2024-09-19
4 AW ABW Aruba 1993 NA <NA> <NA> <NA> 2024-09-19
5 AW ABW Aruba 1994 NA <NA> <NA> <NA> 2024-09-19
6 AW ABW Aruba 1995 NA <NA> <NA> <NA> 2024-09-19
7 AW ABW Aruba 1996 NA <NA> <NA> <NA> 2024-09-19
8 AW ABW Aruba 1997 NA <NA> <NA> <NA> 2024-09-19
9 AW ABW Aruba 1998 NA <NA> <NA> <NA> 2024-09-19
10 AW ABW Aruba 1999 NA <NA> <NA> <NA> 2024-09-19
# ℹ 7,151 more rowsggplot(data = female_labor, mapping = aes(x = date, y = fem_lab_part)) +
geom_line(mapping = aes(group = country), alpha = .1) +
geom_smooth() +
scale_y_continuous(labels = percent_format(scale = 1)) +
labs(
title = "Labor force participation",
x = "Year",
y = "Percent of total labor force which is female",
caption = "Source: World Bank"
)
By default, wb_data() returns queries as data frames in a wide format. So if we request multiple indicators, each indicator will be stored in its own column.
female_vars <- wb_data(
indicator = c(
"fem_lab_part" = "SL.TLF.TOTL.FE.ZS",
"fem_educ_sec" = "SE.SEC.CUAT.UP.FE.ZS"
),
start_date = 1990,
end_date = 2022
)
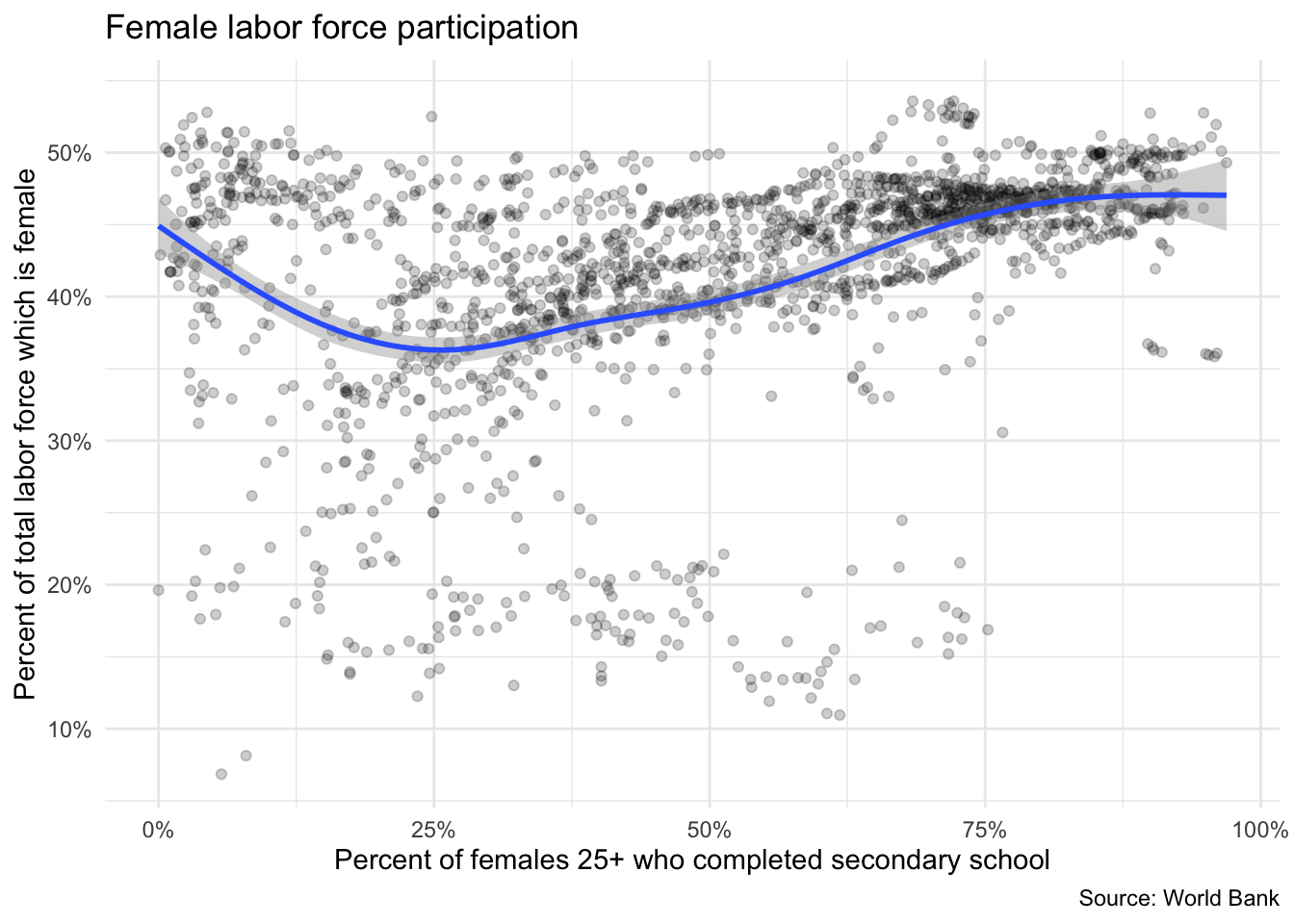
ggplot(data = female_vars, mapping = aes(x = fem_educ_sec, y = fem_lab_part)) +
geom_point(alpha = .2) +
geom_smooth() +
scale_x_continuous(labels = label_percent(scale = 1)) +
scale_y_continuous(labels = label_percent(scale = 1)) +
labs(
title = "Female labor force participation",
x = "Percent of females 25+ who completed secondary school",
y = "Percent of total labor force which is female",
caption = "Source: World Bank"
)
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.4.1 (2024-06-14)
os macOS Sonoma 14.6.1
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/New_York
date 2024-10-08
pandoc 3.4 @ /usr/local/bin/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
! package * version date (UTC) lib source
cli 3.6.3 2024-06-21 [1] RSPM (R 4.4.0)
P digest 0.6.35 2024-03-11 [?] CRAN (R 4.3.1)
P evaluate 0.24.0 2024-06-10 [?] CRAN (R 4.4.0)
P fastmap 1.2.0 2024-05-15 [?] CRAN (R 4.4.0)
P here 1.0.1 2020-12-13 [?] CRAN (R 4.3.0)
P htmltools 0.5.8.1 2024-04-04 [?] CRAN (R 4.3.1)
P htmlwidgets 1.6.4 2023-12-06 [?] CRAN (R 4.3.1)
P jsonlite 1.8.8 2023-12-04 [?] CRAN (R 4.3.1)
P knitr 1.47 2024-05-29 [?] CRAN (R 4.4.0)
renv 1.0.7 2024-04-11 [1] CRAN (R 4.4.0)
P rlang 1.1.4 2024-06-04 [?] CRAN (R 4.3.3)
P rmarkdown 2.27 2024-05-17 [?] CRAN (R 4.4.0)
P rprojroot 2.0.4 2023-11-05 [?] CRAN (R 4.3.1)
P sessioninfo 1.2.2 2021-12-06 [?] CRAN (R 4.3.0)
P xfun 0.45 2024-06-16 [?] CRAN (R 4.4.0)
P yaml 2.3.8 2023-12-11 [?] CRAN (R 4.3.1)
[1] /Users/soltoffbc/Projects/info-5001/course-site/renv/library/macos/R-4.4/aarch64-apple-darwin20
[2] /Users/soltoffbc/Library/Caches/org.R-project.R/R/renv/sandbox/macos/R-4.4/aarch64-apple-darwin20/f7156815
P ── Loaded and on-disk path mismatch.
──────────────────────────────────────────────────────────────────────────────Footnotes
Alternatively, you can use the web interface to determine specific indicators and their IDs.↩︎