Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
Data
The data are stored as a CSV (comma separated values) file in the data folder of your repository. Let’s read it from there and save it as an object called wdi.
The data is stored in a CSV (Comma-Separated Values) file in the data folder of the repository. We’ll import the data and save it as an object called wdi.
The mapping argument defines which variables in the data frame are mapped with specific aesthetics, or the visual channels used to communicate information in the graph.
ggplot( data =wdi, mapping =aes(x =gdp, y =life_exp))
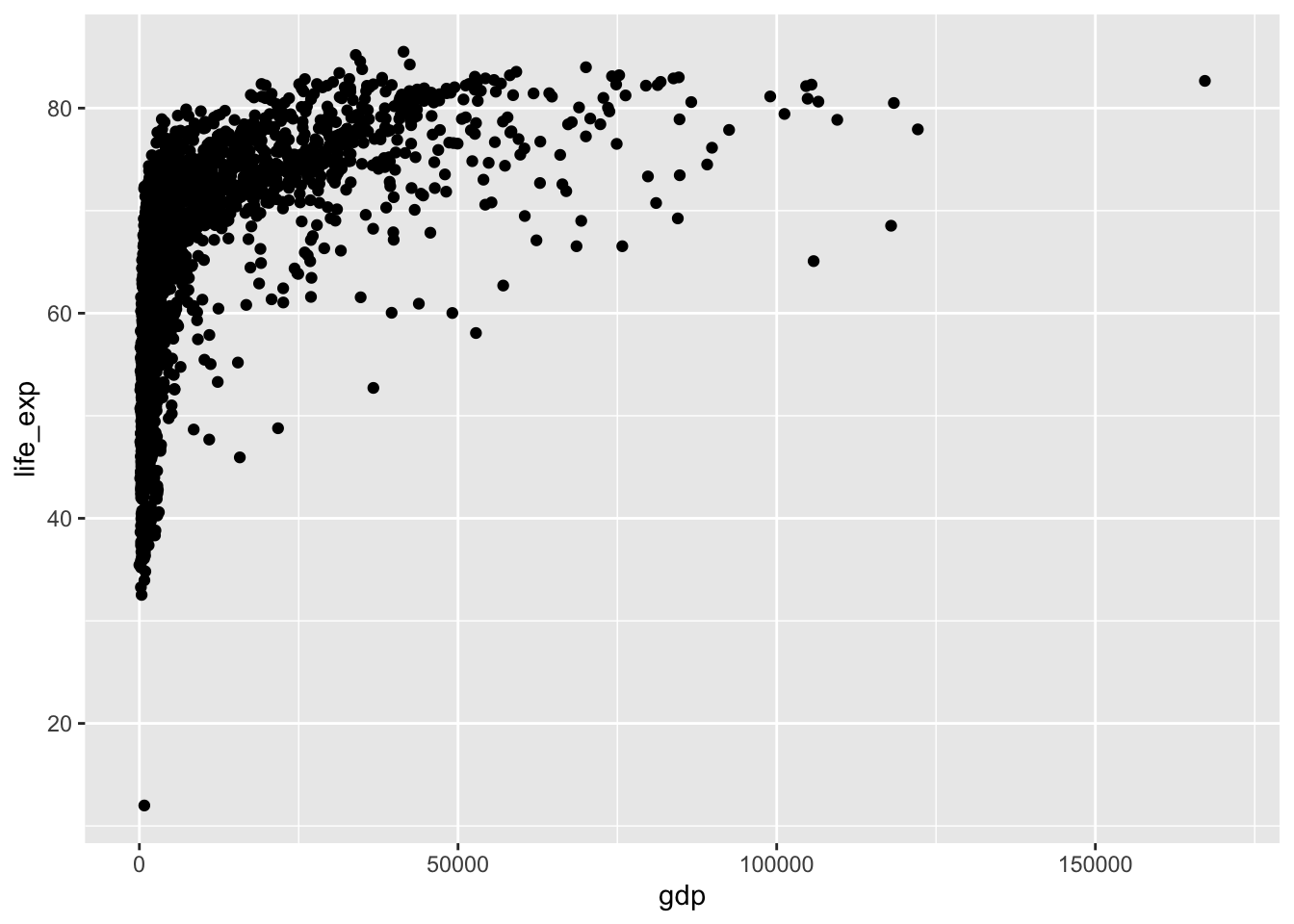
The geom_*() function specifies the type of plot we want to use to represent the data. In the code below, we use geom_point() which creates a plot where each observation is represented by a point.
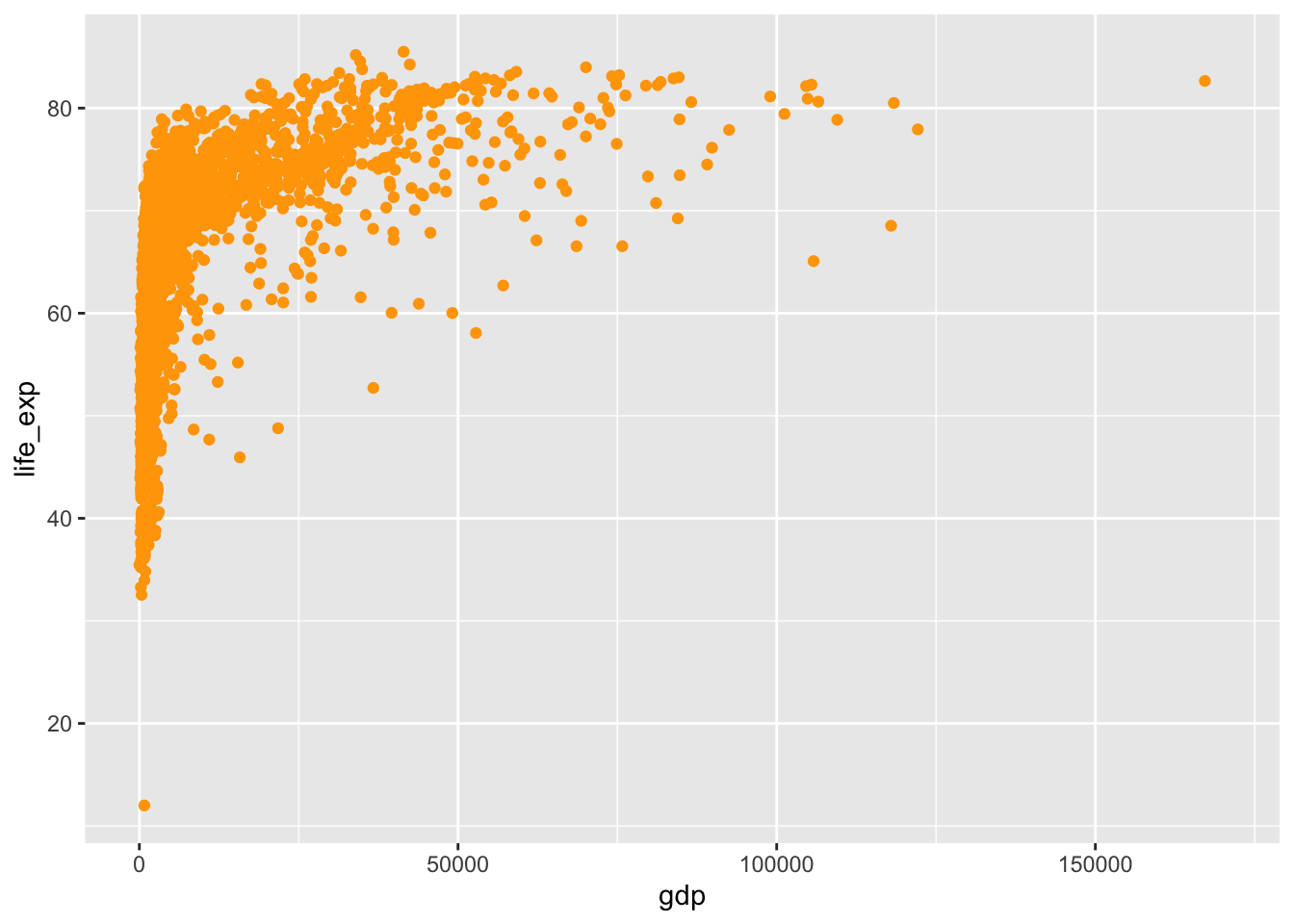
ggplot( data =wdi, mapping =aes(x =gdp, y =life_exp))+geom_point(color ="orange")
Warning: Removed 639 rows containing missing values or values outside the scale range
(`geom_point()`).
Step 2 - Your turn
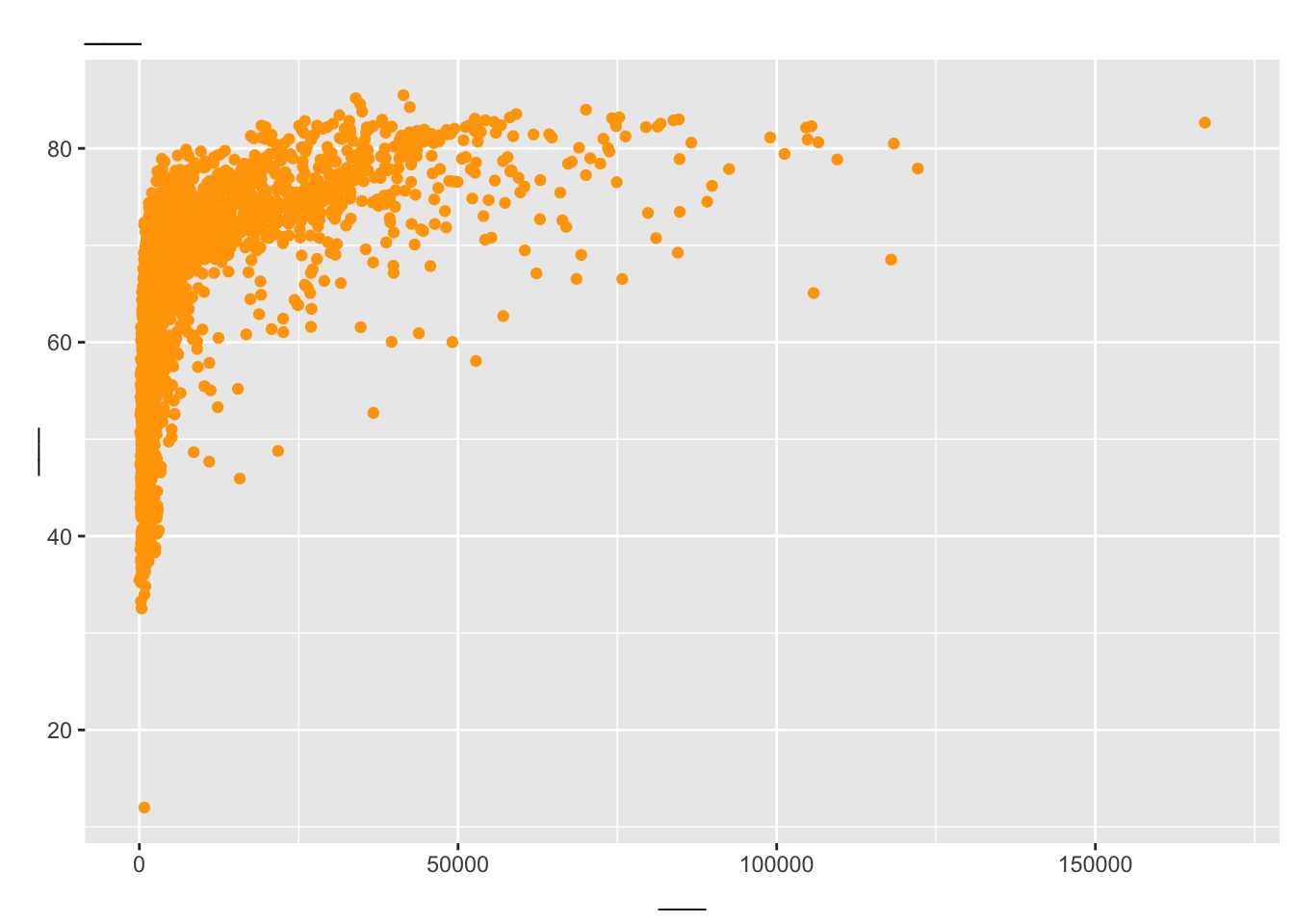
Add labels for the title and \(x\) and \(y\) axes.
ggplot( data =wdi, mapping =aes(x =gdp, y =life_exp))+geom_point(color ="orange")+labs( x ="___", y ="___", title ="___")
Warning: Removed 639 rows containing missing values or values outside the scale range
(`geom_point()`).
Step 3 - Your turn
An aesthetic is a visual property of one of the objects in your plot. Commonly used aesthetic options are:
color
fill
shape
size
alpha (transparency)
Modify the plot below, so the color of the points is based on the variable region.
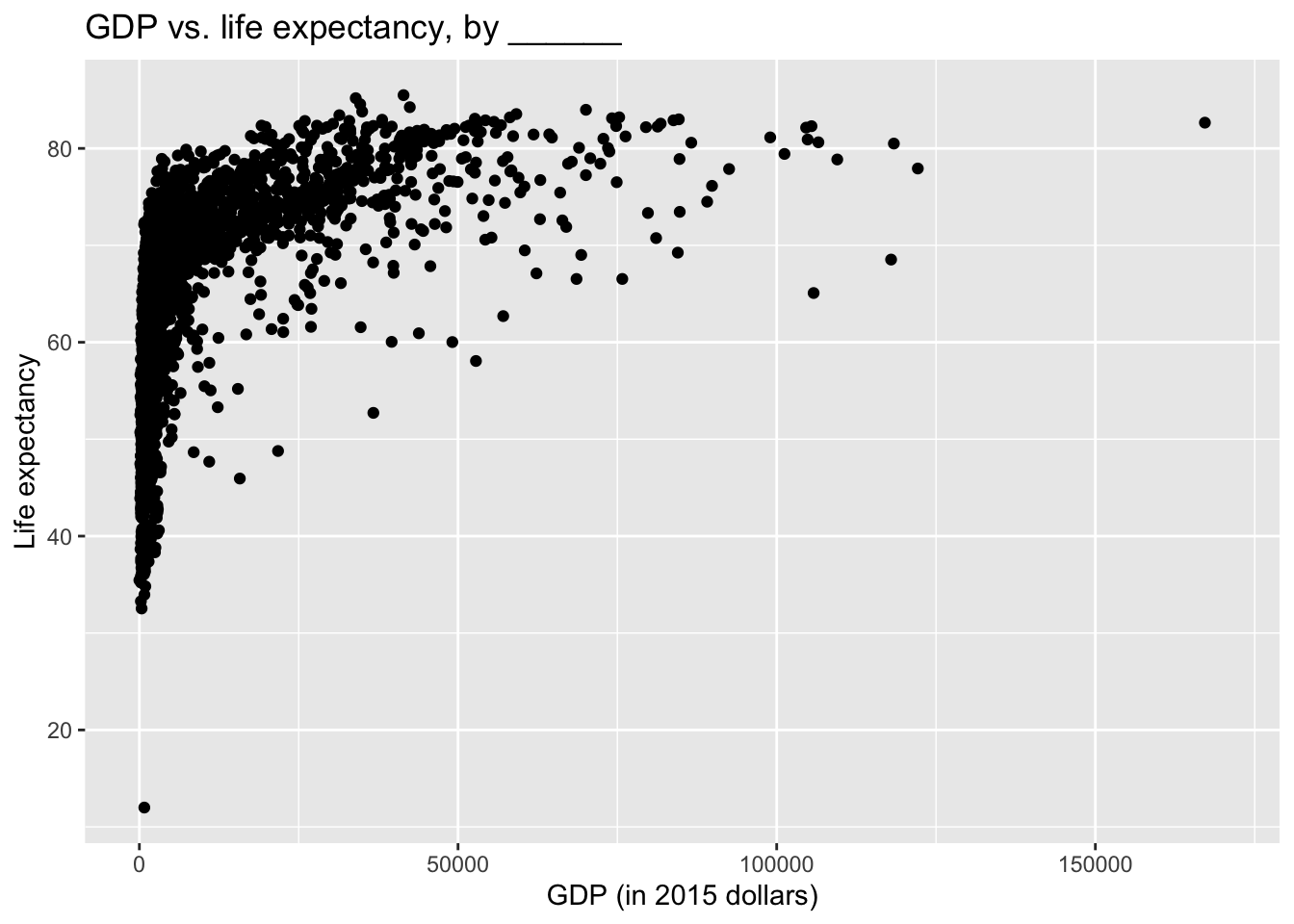
ggplot( data =wdi, mapping =aes(x =gdp, y =life_exp))+geom_point()+labs( x ="GDP (in 2015 dollars)", y ="Life expectancy", title ="GDP vs. life expectancy, by ______")
Warning: Removed 639 rows containing missing values or values outside the scale range
(`geom_point()`).
Step 4 - Your turn
Expand on your plot from the previous step to make the size of your points based on pop.
# add code here
Step 5 - Your turn
Expand on your plot from the previous step to make the transparency (alpha) of the points 0.5.
# add code here
Step 6 - Your turn
Expand on your plot from the previous step by using facet_wrap() to display the association between GDP and life expectancy for each region.
# add code here
Step 7 - Demo
Improve your plot from the previous step by making the \(x\) and \(size\) guides more legible.